我面临一个问题,需要支持快速查找第k大元素的队列数据结构。
该数据结构的要求如下:
队列中的元素不一定是整数,但它们必须可比较,即我们可以在比较两个元素时确定哪个更大(它们也可以相等)。
数据结构必须支持enqueue(将元素添加到队尾)和dequeue(从队头删除元素)。
它可以快速找到队列中第k大的元素,请注意k不是常数。
您可以假设enqueue、dequeue和查找第k大元素的操作具有相同的频率。
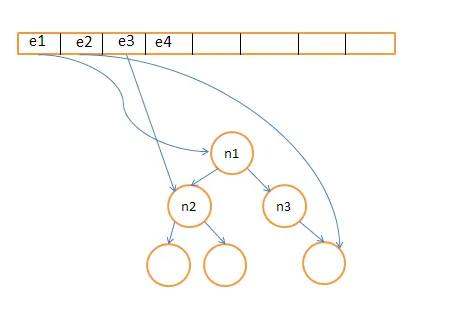
为简单起见,假设所有元素都是不同的。
Enqueue(x):将x首先插入到树中,假设对应的节点是节点t,我们将pair(x,指向节点t的指针)添加到队列中。
Dequeue:假设(e1,node1)是队列头部的元素,node1是对应于e1的指向树的指针。我们从树中删除node1并从队列中删除(e1,node1)。
查找第K大的元素:假设根节点是节点root,它的两个子节点是节点left和节点right(假设它们都存在),我们将K与nroot进行比较,可能会出现三种情况:
如果 K< nleft,则在nroot的左子树中查找第K大的元素;
如果 K>nroot-nright,则在nroot的右子树中查找第(K-nroot+nright)大的元素;
否则,nroot就是我们要找的节点。
所有这三个操作的时间复杂度均为O(logN),其中N是当前队列中的元素数量。
如何加速上述操作?使用什么数据结构以及如何使用?
k是常数(实际上不是),你可以使用堆来跟踪第k个元素。这将允许O(1)查找第k个元素和O(logN)进行入队/出队操作。 - smocking