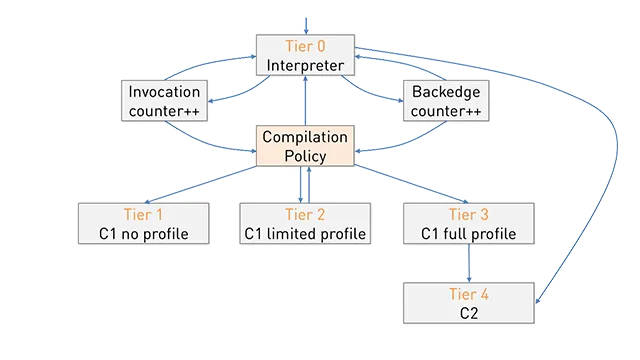
最近在使用-XX:+PrintCompilation(JDK 8r111)来检查方法编译时,我注意到了一个新的列,这个列在文档中没有提到,可以在这里找到相关内容:
this column
|
|
v
600 1 s 3 java.util.Hashtable::get (69 bytes)
601 4 3 java.lang.Character::toLowerCase (6 bytes)
601 8 3 java.io.UnixFileSystem::normalize (75 bytes)
602 12 3 java.lang.ThreadLocal::get (38 bytes)
602 14 3 java.lang.ThreadLocal$ThreadLocalMap::getEntry (42 bytes)
602 18 2 java.lang.String::startsWith (72 bytes)
602 10 4 java.lang.String::equals (81 bytes)
602 2 % 4 java.lang.String::hashCode @ 24 (55 bytes)
602 16 s! 3 sun.misc.URLClassPath::getLoader (197 bytes)
603 23 n 0 java.lang.System::arraycopy (native) (static)
604 27 n 0 sun.misc.Unsafe::getObjectVolatile (native)
你知道这是什么意思吗?它似乎在0和3之间变化,本地方法始终为0,其他方法始终为非零。