我想使用循环神经网络(RNN)进行时间序列预测,使用96个向前的步骤来预测未来96个步骤。为此,我有以下代码:
在这里,您可以获得一些测试数据(不用关心实际值,因为我是编造的,只要形状重要)下载测试数据。
如何解释
#Import modules
import pandas as pd
import numpy as np
import tensorflow as tf
from sklearn.preprocessing import StandardScaler
from tensorflow import keras
# Define the parameters of the RNN and the training
epochs = 1
batch_size = 50
steps_backwards = 96
steps_forward = 96
split_fraction_trainingData = 0.70
split_fraction_validatinData = 0.90
randomSeedNumber = 50
helpValueStrides = int(steps_backwards /steps_forward)
#Read dataset
df = pd.read_csv('C:/Users1/Desktop/TestValues.csv', sep=';', header=0, low_memory=False, infer_datetime_format=True, parse_dates={'datetime':[0]}, index_col=['datetime'])
# standardize data
data = df.values
indexWithYLabelsInData = 0
data_X = data[:, 0:3]
data_Y = data[:, indexWithYLabelsInData].reshape(-1, 1)
scaler_standardized_X = StandardScaler()
data_X = scaler_standardized_X.fit_transform(data_X)
data_X = pd.DataFrame(data_X)
scaler_standardized_Y = StandardScaler()
data_Y = scaler_standardized_Y.fit_transform(data_Y)
data_Y = pd.DataFrame(data_Y)
# Prepare the input data for the RNN
series_reshaped_X = np.array([data_X[i:i + (steps_backwards+steps_forward)].copy() for i in range(len(data) - (steps_backwards+steps_forward))])
series_reshaped_Y = np.array([data_Y[i:i + (steps_backwards+steps_forward)].copy() for i in range(len(data) - (steps_backwards+steps_forward))])
timeslot_x_train_end = int(len(series_reshaped_X)* split_fraction_trainingData)
timeslot_x_valid_end = int(len(series_reshaped_X)* split_fraction_validatinData)
X_train = series_reshaped_X[:timeslot_x_train_end, :steps_backwards]
X_valid = series_reshaped_X[timeslot_x_train_end:timeslot_x_valid_end, :steps_backwards]
X_test = series_reshaped_X[timeslot_x_valid_end:, :steps_backwards]
Y_train = series_reshaped_Y[:timeslot_x_train_end, steps_backwards:]
Y_valid = series_reshaped_Y[timeslot_x_train_end:timeslot_x_valid_end, steps_backwards:]
Y_test = series_reshaped_Y[timeslot_x_valid_end:, steps_backwards:]
# Build the model and train it
np.random.seed(randomSeedNumber)
tf.random.set_seed(randomSeedNumber)
model = keras.models.Sequential([
keras.layers.SimpleRNN(10, return_sequences=True, input_shape=[None, 3]),
keras.layers.SimpleRNN(10, return_sequences=True),
keras.layers.Conv1D(16, helpValueStrides, strides=helpValueStrides),
keras.layers.TimeDistributed(keras.layers.Dense(1))
])
model.compile(loss="mean_squared_error", optimizer="adam", metrics=['mean_absolute_percentage_error'])
history = model.fit(X_train, Y_train, epochs=epochs, batch_size=batch_size, validation_data=(X_valid, Y_valid))
#Predict the test data
Y_pred = model.predict(X_test)
prediction_lastValues_list=[]
for i in range (0, len(Y_pred)):
prediction_lastValues_list.append((Y_pred[i][0][1 - 1]))
# Create thw dataframe for the whole data
wholeDataFrameWithPrediciton = pd.DataFrame((X_test[:,1]))
wholeDataFrameWithPrediciton.rename(columns = {indexWithYLabelsInData:'actual'}, inplace = True)
wholeDataFrameWithPrediciton.rename(columns = {1:'Feature 1'}, inplace = True)
wholeDataFrameWithPrediciton.rename(columns = {2:'Feature 2'}, inplace = True)
wholeDataFrameWithPrediciton['predictions'] = prediction_lastValues_list
wholeDataFrameWithPrediciton['difference'] = (wholeDataFrameWithPrediciton['predictions'] - wholeDataFrameWithPrediciton['actual']).abs()
wholeDataFrameWithPrediciton['difference_percentage'] = ((wholeDataFrameWithPrediciton['difference'])/(wholeDataFrameWithPrediciton['actual']))*100
# Inverse the scaling (traInv: transformation inversed)
data_X_traInv = scaler_standardized_X.inverse_transform(data_X)
data_Y_traInv = scaler_standardized_Y.inverse_transform(data_Y)
series_reshaped_X_notTransformed = np.array([data_X_traInv[i:i + (steps_backwards+steps_forward)].copy() for i in range(len(data) - (steps_backwards+steps_forward))])
X_test_notTranformed = series_reshaped_X_notTransformed[timeslot_x_valid_end:, :steps_backwards]
predictions_traInv = scaler_standardized_Y.inverse_transform(wholeDataFrameWithPrediciton['predictions'].values.reshape(-1, 1))
edictions_traInv = wholeDataFrameWithPrediciton['predictions'].values.reshape(-1, 1)
# Create thw dataframe for the inversed transformed data
wholeDataFrameWithPrediciton_traInv = pd.DataFrame((X_test_notTranformed[:,0]))
wholeDataFrameWithPrediciton_traInv.rename(columns = {indexWithYLabelsInData:'actual'}, inplace = True)
wholeDataFrameWithPrediciton_traInv.rename(columns = {1:'Feature 1'}, inplace = True)
wholeDataFrameWithPrediciton_traInv['predictions'] = predictions_traInv
wholeDataFrameWithPrediciton_traInv['difference_absolute'] = (wholeDataFrameWithPrediciton_traInv['predictions'] - wholeDataFrameWithPrediciton_traInv['actual']).abs()
wholeDataFrameWithPrediciton_traInv['difference_percentage'] = ((wholeDataFrameWithPrediciton_traInv['difference_absolute'])/(wholeDataFrameWithPrediciton_traInv['actual']))*100
wholeDataFrameWithPrediciton_traInv['difference'] = (wholeDataFrameWithPrediciton_traInv['predictions'] - wholeDataFrameWithPrediciton_traInv['actual'])
在这里,您可以获得一些测试数据(不用关心实际值,因为我是编造的,只要形状重要)下载测试数据。
如何解释
Y_pred数据的输出?哪些值能够预测我未来96步的数值?我已经附上了“Y_pred”数据的屏幕截图。一次使用5个输出神经元的最后一层,另一次仅使用1个输出神经元。有人能告诉我如何解释“Y_pred”数据,即RNN到底在预测什么吗?我可以使用RNN模型输出(最后一层)中的任何值。“Y_pred”数据始终具有形状(X_test的批大小,时间序列,输出神经元的数量)。我的问题针对的是最后一个维度。我认为这些可能是特征,但在我的情况下并不是这样,因为我只有1个输出特征(您可以在Y_train、Y_test和Y_valid数据的形状中看到这一点)。
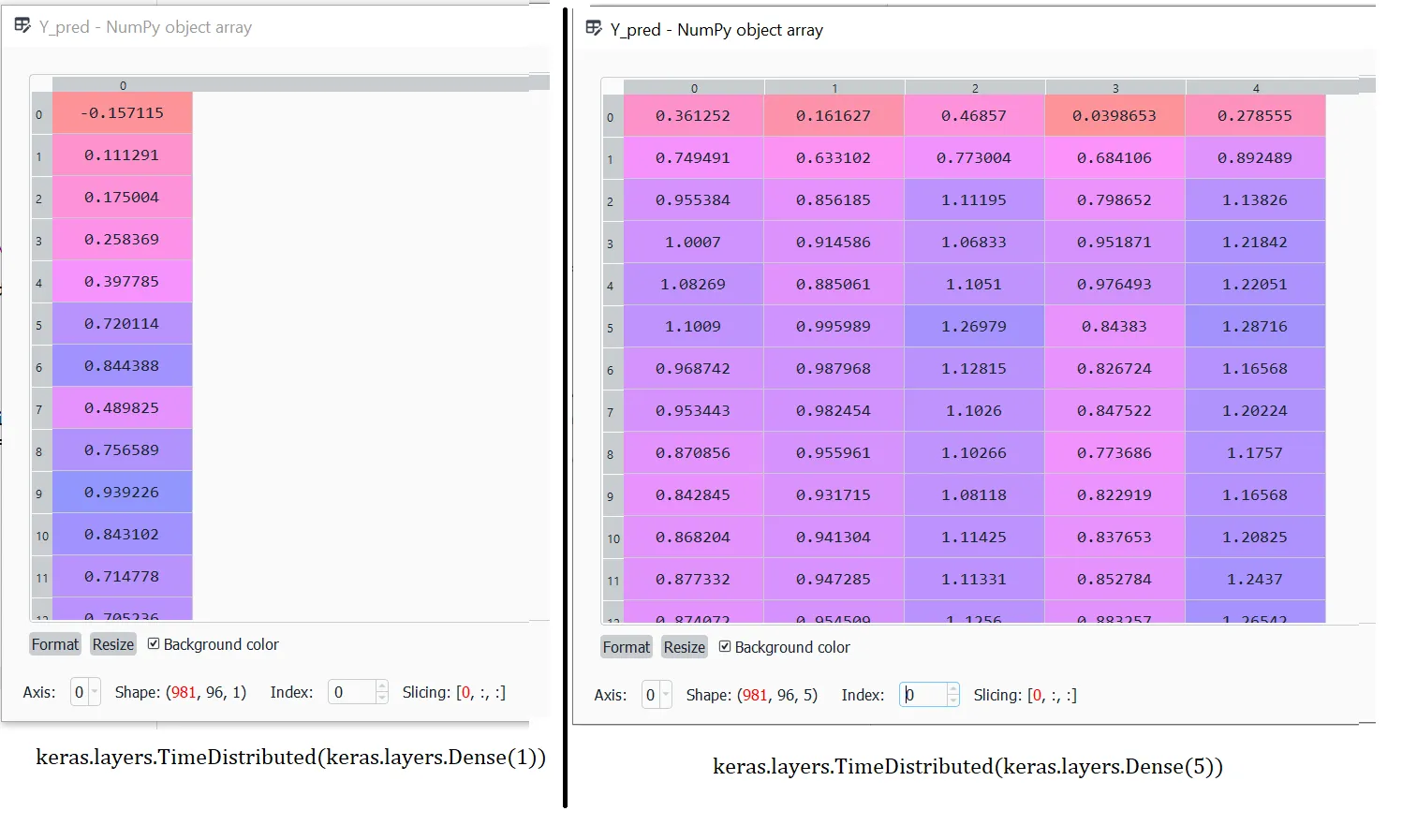
model = keras.models.Sequential([...开始,并且训练命令在行model.compile(loss="mean_squared_error", optimizer="adam", metrics=['mean_absolute_percentage_error'])和history = model.fit(X_train, Y_train, ...中定义。 - PeterBeX_train、X_valid和X_test时,您应该使用:-steps_backwards而不是:steps_backwards,这种情况有可能发生吗? - The Guy with The Hat:-steps_backwards而不是:steps_backwards没有任何区别。无论如何,更重要的问题(也是我提出这个问题并将奖励给你的原因)是RNN到底在预测什么?我如何解释RNN的输出结果?你能否在这个话题上给我更多的见解? - PeterBe