我有一些代码包含了 zip(*G)[0](在其他地方,还有一个不同的G,zip(*G)[1])。G 是一个元组列表。它返回G中每个元组的第一个元素(或一般地,对于zip(*G)[n],是第n-1个)作为元组的列表。例如:
>>> G = [(1, 2, 3), ('a', 'b', 'c'), ('you', 'and', 'me')]
>>> zip(*G)[0]
(1, 'a', 'you')
>>> zip(*G)[1]
(2, 'b', 'and')
是否有更有效但同样紧凑的方法来做到这一点?我可以接受标准库中的任何内容。在我的用例中,G 中的每个元组至少为长度 n,因此不必担心 zip 停止在最小长度元组的情况(即 zip(*G)[n] 总是被定义的)。
如果没有,我想我只会坚持将 zip 包装在 list() 中。
P.S.,我知道这是不必要的优化。我只是好奇。
更新:
如果有人在意的话,我选择了 zip(*G) 选项。首先,这让我为数据提供有意义的名称。我的 G 实际上由长度为 2 的元组组成(表示分子和分母)。列表推导式只会比 zip 稍微更可读,但这种方法更好(并且由于大多数情况下 zip 是我在列表推导式中迭代的列表,所以这使得事情更平坦)。
其次,正如 @thewolf 和 @Sven Marnach 的答案所指出的那样,对于较小的列表,这种方法更快。我的 G 在大多数情况下实际上不是很大(如果它很大,那么这肯定不会是代码的瓶颈!)。
但是有比我预期的更多方法可以做到这一点,包括 Python 3 中的新功能 a, *b, c = G,我甚至不知道该怎么用。
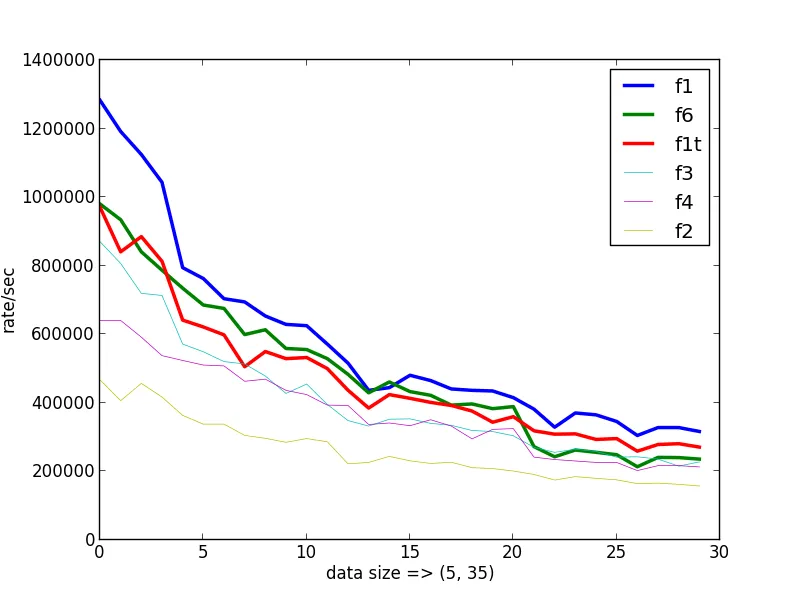
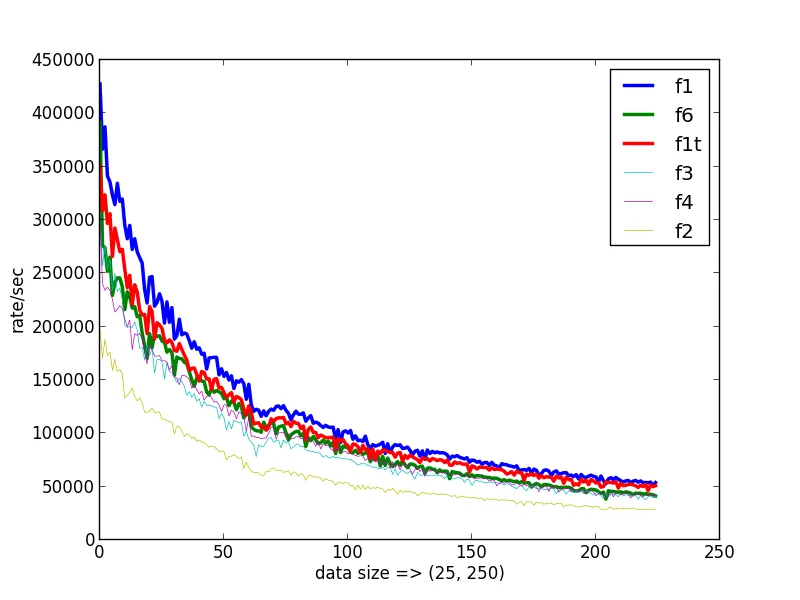
f6()这个函数,你有什么想法吗? - martineau