这里的技巧是检查点击链接查看其他页面时输入和输出的请求。检查的方法是使用Chrome的检查工具(通过按下)或在Firefox中安装Firebug扩展程序。本答案将使用Chrome的检查工具。请参见下面的设置。
现在,我们想要看到的是向另一个页面发送的GET请求或更改页面的POST请求。在打开工具的情况下,单击页面编号。短暂的一刻内,只会出现一个请求,并且它是POST方法。所有其他元素都会快速跟随并填充页面。请参见下面的内容。
单击上面的POST方法。它应该带来一个子窗口,其中有选项卡。单击标题选项卡。此页面列出请求标头,基本上是站点需要的您的身份验证信息等内容,以便连接(其他人可以比我解释得更好)。
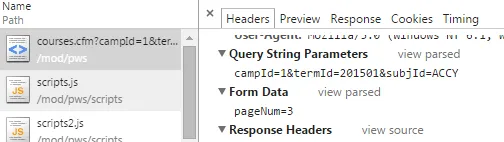
每当URL具有变量,例如页码、位置标记或类别时,很可能站点使用查询字符串。长话短说,它类似于SQL查询(实际上,有时它就是SQL查询),允许站点提取您所需的信息。如果是这种情况,则可以检查查询字符串参数的请求标头。向下滚动一点,您应该会找到它。
如您所见,查询字符串参数与我们的URL中的变量匹配。稍微向下滚动一点,您可以看到下面有一个pageNum:2的表单数据。这是关键。
POST请求更常见地称为表单请求,因为这些是在提交表单、登录网站等情况下进行的请求。基本上,几乎任何需要提交信息的事情都属于此类。大多数人看不到的是,POST请求有一个它们遵循的URL。这种情况的一个很好的例子是当您登录网站并且非常简短地看到您的地址栏变成某种无意义的URL,然后定格在/index.html或类似的位置。
上面的段落基本上意味着您可以(但并不总是)将表单数据附加到您的URL中,并且它将在执行时为您执行POST请求。要知道要附加的确切字符串,请单击“查看源代码”。
通过将其添加到URL中测试它是否有效。
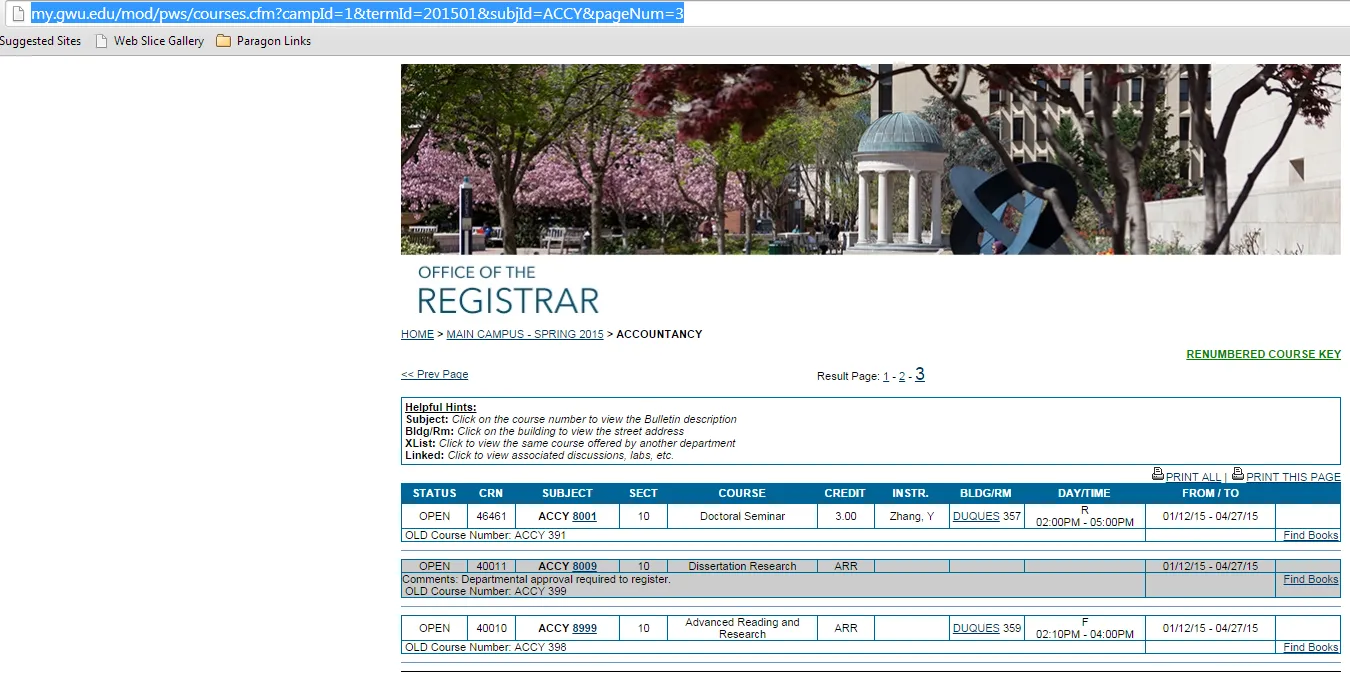
Et voila,它可以工作了。现在,真正的挑战是自动获取最后一页并抓取所有页面。您的代码几乎已经完成了。剩下的事情是获取页面数,构建要抓取的URL列表,并对它们进行迭代。
修改后的代码如下:
from bs4 import BeautifulSoup as bsoup
import requests as rq
import re
base_url = 'http://my.gwu.edu/mod/pws/courses.cfm?campId=1&termId=201501&subjId=ACCY'
r = rq.get(base_url)
soup = bsoup(r.text)
page_count_links = soup.find_all("a",href=re.compile(r".*javascript:goToPage.*"))
try:
num_pages = int(page_count_links[-1].get_text())
except IndexError:
num_pages = 1
url_list = ["{}&pageNum={}".format(base_url, str(page)) for page in range(1, num_pages + 1)]
with open("results.txt","wb") as acct:
for url_ in url_list:
print "Processing {}...".format(url_)
r_new = rq.get(url_)
soup_new = bsoup(r_new.text)
for tr in soup_new.find_all('tr', align='center'):
stack = []
for td in tr.findAll('td'):
stack.append(td.text.replace('\n', '').replace('\t', '').strip())
acct.write(", ".join(stack) + '\n')
我们使用正则表达式来获取正确的链接。然后使用列表推导式构建URL字符串列表。最后,我们对它们进行迭代。
Processing http://my.gwu.edu/mod/pws/courses.cfm?campId=1&termId=201501&subjId=ACCY&pageNum=1...
Processing http://my.gwu.edu/mod/pws/courses.cfm?campId=1&termId=201501&subjId=ACCY&pageNum=2...
Processing http://my.gwu.edu/mod/pws/courses.cfm?campId=1&termId=201501&subjId=ACCY&pageNum=3...
[Finished in 6.8s]

希望这有所帮助。
编辑:
出于无聊,我想我刚刚创建了整个班级目录的爬虫。另外,我更新了上面和下面的代码,以防只有一个页面可用时出错。
from bs4 import BeautifulSoup as bsoup
import requests as rq
import re
spring_2015 = "http://my.gwu.edu/mod/pws/subjects.cfm?campId=1&termId=201501"
r = rq.get(spring_2015)
soup = bsoup(r.text)
classes_url_list = [c["href"] for c in soup.find_all("a", href=re.compile(r".*courses.cfm\?campId=1&termId=201501&subjId=.*"))]
print classes_url_list
with open("results.txt","wb") as acct:
for class_url in classes_url_list:
base_url = "http://my.gwu.edu/mod/pws/{}".format(class_url)
r = rq.get(base_url)
soup = bsoup(r.text)
page_count_links = soup.find_all("a",href=re.compile(r".*javascript:goToPage.*"))
try:
num_pages = int(page_count_links[-1].get_text())
except IndexError:
num_pages = 1
url_list = ["{}&pageNum={}".format(base_url, str(page)) for page in range(1, num_pages + 1)]
for url_ in url_list:
print "Processing {}...".format(url_)
r_new = rq.get(url_)
soup_new = bsoup(r_new.text)
for tr in soup_new.find_all('tr', align='center'):
stack = []
for td in tr.findAll('td'):
stack.append(td.text.replace('\n', '').replace('\t', '').strip())
acct.write(", ".join(stack) + '\n')
POST请求即可。请查看下面的答案。 - WGS