我有一个问题。这是我的初始示例数据库:
nam <- c("Marco", "Clara")
code <- c("The liquidations code for Marco are: 51-BMR05, 74-VAD08, 176-VNF09.",
"The liquidations code for Clara are: 88-BMR05, 90-VAD08, 152-VNF09.")
df <- data.frame(name,code)
这看起来像这样:
这样

所以我希望冒号后面的代码能够被分离并成为一个具有相同名称的记录。也就是说,数据库是这样转换和完成的:
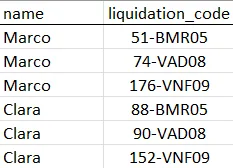
我需要知道在R中是否有任何方法可以帮助我简化和加速这项工作。我已经在Excel中做了一些例子。提前感谢大家的帮助。