我有一个已排序的数组 X[k]。 现在我想找到
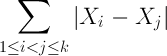
我尝试了这个方法
int ans=0;
for(int i=1;i<=k;i++)
{
for(int j=i+1;j<=k;j++)
{
ans+=abs(X[i]-X[j]);
}
}
我通过使用上述解决方案得到了正确的答案,但它并不是最优化的,在某些情况下会超时。 有没有一种实现这个算法的方式可以使复杂度最小化?
我有一个已排序的数组 X[k]。 现在我想找到
我尝试了这个方法
int ans=0;
for(int i=1;i<=k;i++)
{
for(int j=i+1;j<=k;j++)
{
ans+=abs(X[i]-X[j]);
}
}
我通过使用上述解决方案得到了正确的答案,但它并不是最优化的,在某些情况下会超时。 有没有一种实现这个算法的方式可以使复杂度最小化?
Sigma[i] Sigma[j>i] abs(Xi-Xj)。(假设i,j的索引在1到k之间)abs,从而得到以下公式:Sigma[i] Sigma[j>i] (Xj - Xi)
Sigma[i] Sigma[j>i] Xj - Sigma[i] Sigma[j>i] Xi
j,第一个求和式中Xj出现了多少次?当=1和=2时,X2只出现一次;当=1和=3或=2和=3时,X3出现两次。通常有Xj出现 j-1次,所以它对总和的贡献是(j-1)Xj(假设从1开始索引)。Xi出现了(k-i)次,因此对总和的贡献为(k-i)Xi。Sigma[j](j-1)Xj - Sigma[i](k-i)Xi。这可以简化为:Sigma[i]((2i-k-1)Xi)
这是以O(n)的时间复杂度计算,而不是普通算法的O(n^2)。
假设这里的sorted意味着
对于任何1 ≤ i ≤ j ≤ N,都有 Xi ≤ Xj。
并将您的计算目标表示为F
令 F(X1..N) = Σ1 ≤ i < j ≤ N|Xi - Xj|
那么我们有
F(X 1..N) = F(X 2..N) + Σ 1 ≤ i ≤ N|X i - X 1| = F(X 3..N) + Σ 2 ≤ i ≤ N|X i - X 2| + Σ 1 ≤ i ≤ N|X i - X 1| = F(X 4..N) + ...因此,我们有以下迭代来计算总和:
/*
* assuming here the data type int is suitable for holding the result
* N is the array length, X is the sorted array
*/
int sorted_sub_sum(int N, const int *X)
{
int ret = 0;
int tmp_sum = 0;
int i;
for (i = 0; i < N; i++)
tmp_sum += X[i] - X[0];
for (i = 0; i < N - 1; i++)
{
ret += tmp_sum;
tmp_sum -= (N - i - 1) * (X[i + 1] - X[i]);
}
return ret;
}
我对这段代码进行了一些简单的测试(例如数组{1,2,4,9}和{1,2,4,9,17})。如果您发现任何错误,请告诉我。
编辑:我没有仔细阅读原帖的定义,在我的答案中N表示数组长度,就像原问题中的k一样。对此给您带来的不便深感抱歉。
你可以用非常简单的方式来实现这个,时间复杂度为O(n),正如其他答案中提到的,abs函数是多余的:
int ans = 0;
for (int i = 0; i < X.lengh; i++)
ans += ((X.length - i) * (i)) * (X[i] - X[i-1]);
这种方法基于一个事实,即 X[i] - X[i-2] = 2(X[i] - X[i-1]) - (X[i-1] - X[i-2]),这使您可以仅中断每个计算并计算数组中相邻两个数字相减的总次数。
我们可以摆脱 abs(数组已排序),在结果中 x_1 出现了 (k-1) 次负数,X_2 出现了 1 次正数和 k-2 次负数,意味着我们总共计算了 k-3 次负数和... x_(k-1) 出现了 k-3 次正数,x_k 出现了 k-1 次正数,因此我们有以下简化的求和:
int coef = 1-k;
int sum = 0;
for(int i=0;i<k;i++)
{
sum += coef * x[i];
coef += 2;
}