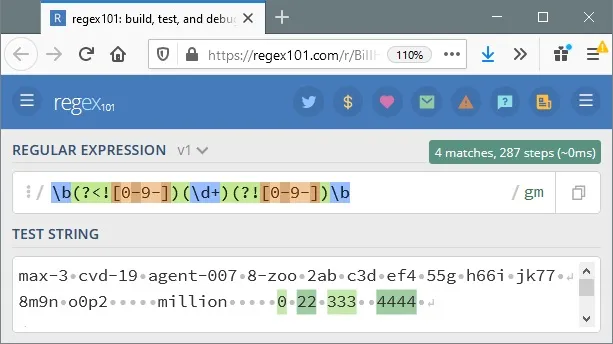
我想从字符串中删除所有数字,但是下面的代码也会删除任何单词中包含的数字,而我显然不希望如此。我已经尝试了许多正则表达式,但没有成功。
谢谢!
我正在尝试从字符串中删除所有数字。然而,下面的代码还会删除任何单词中包含的数字,这显然不是我想要的。我已经尝试过许多正则表达式,但都没有成功。
谢谢!
s = "This must not b3 delet3d, but the number at the end yes 134411"
s = re.sub("\d+", "", s)
print s
结果:
这部分内容不能被删除,但是末尾的数字可以被删除。