我如何使用 new 声明一个二维数组?
例如,对于“普通”的数组,我会这样做:
int* ary = new int[Size]
但是
int** ary = new int[sizeY][sizeX]
a) 不能工作/编译,b) 也没有实现什么:
int ary[sizeY][sizeX]
做什么。
我如何使用 new 声明一个二维数组?
例如,对于“普通”的数组,我会这样做:
int* ary = new int[Size]
但是
int** ary = new int[sizeY][sizeX]
a) 不能工作/编译,b) 也没有实现什么:
int ary[sizeY][sizeX]
做什么。
auto arr2d = new int [nrows][CONSTANT];
请参考此回答。像gcc这样允许使用可变长度数组作为C++扩展的编译器可以使用new如此展示的方式获得完全运行时变量数组维度功能,就像C99一样,但是便携式ISO C ++仅限于第一个维度为可变。
另一个高效的选择是手动将2d索引到一个大的1d数组中,如另一个答案所示,允许与真正的2D数组相同的编译器优化(例如,证明或检查数组之间/重叠)。
否则,您可以使用数组指向数组的指针来允许使用连续的2D数组语法,尽管它不是一个高效的单个大分配。您可以使用循环初始化它,像这样:
int** a = new int*[rowCount];
for(int i = 0; i < rowCount; ++i)
a[i] = new int[colCount];
对于colCount= 5和rowCount = 4,上述内容将产生以下结果:
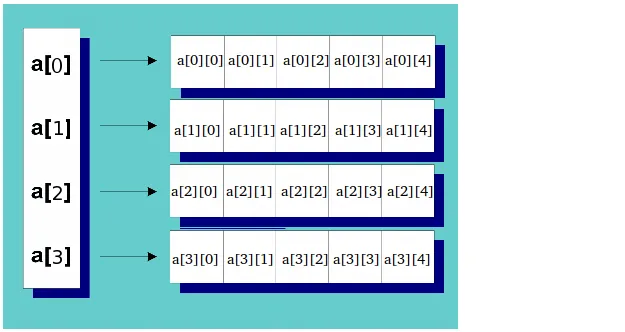
在删除指针数组之前,不要忘记使用循环单独删除每一行。示例请参见另一个答案。
new 分配的任何内容都创建在堆上,并且必须使用 delete 进行释放。只需记住这一点,并确保在完成后从堆中删除此内存,以防止泄漏。 - KekoaT (*ptr)[M] = new T[N][M];才是正确的解决方案……无论有多少个数组指针,也永远无法与数组本身相同…… - The Paramagnetic Croissantint** ary = new int[sizeY][sizeX]
应该是:
int **ary = new int*[sizeY];
for(int i = 0; i < sizeY; ++i) {
ary[i] = new int[sizeX];
}
然后进行清理:
for(int i = 0; i < sizeY; ++i) {
delete [] ary[i];
}
delete [] ary;
编辑:正如Dietrich Epp在评论中指出的,这并不是一个轻量级的解决方案。一种替代方法是使用一个大的内存块:
int *ary = new int[sizeX*sizeY];
// ary[i][j] is then rewritten as
ary[i*sizeY+j]
i*sizeX+j吗?如果我没记错的话,按行主序排列应该是row*numColumns+col。 - arao6虽然这个流行的答案可以给你想要的索引语法,但它在空间和时间上都是双重低效的。有一种更好的方式。
为什么该答案也大又慢
提出的解决方案是创建一个指针的动态数组,然后初始化每个指针到它自己的独立动态数组。这种方法的优点是它给你了你习惯使用的索引语法,所以如果你想要找到位置x,y处的矩阵值,你可以说:
int val = matrix[ x ][ y ];
这个方法有效的原因是 matrix[x] 返回了一个数组指针,然后用 [y] 对其进行索引。简单来说:
int* row = matrix[ x ];
int val = row[ y ];
方便,是吗?我们喜欢我们的[x][y]语法。
但是这种解决方案有一个很大的缺点,那就是它既臃肿又慢。
为什么呢?
它既臃肿又慢的原因实际上是一样的。矩阵中的每个“行”都是单独分配的动态数组。进行堆分配在时间和空间上都很昂贵。分配器需要时间来进行分配,有时候会运行O(n)算法来完成。而且分配器会为每个行数组填充额外的字节以进行簿记和对齐。这个额外的空间会产生额外的开销。当你去释放矩阵时,解分配器还会花费额外的时间,费力地释放每个单独的行分配。这让我感到很闷。
它变慢的另一个原因是这些独立的分配往往存在于内存的不连续部分。一行可能在地址1,000,另一行可能在地址100,000——你明白了吧。这意味着当你遍历矩阵时,你像一个疯子一样跳跃着内存。这往往导致缓存未命中,大大降低了处理时间。
因此,如果你绝对需要可爱的[x][y]索引语法,请使用该解决方案。如果你想要快速和小巧(如果你不关心这些,为什么要在C++中工作?),你需要另一种解决方案。
另一种解决方案
更好的解决方案是将整个矩阵分配为单个动态数组,然后使用你自己的(稍微)聪明的索引数学来访问单元格。这种索引数学只是非常稍微聪明;不,它根本不聪明:它是显而易见的。
class Matrix
{
...
size_t index( int x, int y ) const { return x + m_width * y; }
};
假设你有这样一个index()函数(我想象它是某个类的成员,因为它需要知道矩阵的m_width),那么你就可以访问矩阵数组中的单元格。 矩阵数组的分配方式如下:
array = new int[ width * height ];
所以,这在缓慢而低效的解决方案中的等价物:
array[ x ][ y ]
这在快速、简便的解决方案中是如此实现的:
array[ index( x, y )]
很遗憾,我知道。但你会逐渐习惯的,而且你的CPU会感激你。
class Matrix { int* array; int m_width; public: Matrix( int w, int h ) : m_width( w ), array( new int[ w * h ] ) {} ~Matrix() { delete[] array; } int at( int x, int y ) const { return array[ index( x, y ) ]; } protected: int index( int x, int y ) const { return x + m_width * y; } }; 如果你把这段代码展开来看,它可能会有意义,并且可能会阐明上面的答案。 - OldPeculier#define ROW_COL_TO_INDEX(row, col, num_cols) (row*num_cols + col)
然后你可以这样使用:
int COLS = 4; A[ ROW_COL_TO_INDEX(r, c, COLS) ] = 75;当我们进行矩阵乘法时,这些额外开销确实会影响复杂度为**O(n^3)或Strassen算法的O(n^2.81)**。 - Ash Ketchuma[x][y]实际上是执行*(*(a + x) + y):两个加法和两个内存读取操作。而使用a[index(x, y)]实际上是执行*(a + x + w*y):两个加法、一个乘法和一个内存读取操作。后者通常更可取,因为它能够通过牺牲一次内存读取操作来完成一次乘法操作,而且数据不会被分割,因此不会发生缓存未命中。 - Boris Dalstein在 C++11 中,这是可能的:
auto array = new double[M][N];
这种方式不会初始化内存。要初始化它,请改为执行以下操作:
auto array = new double[M][N]();
示例程序(使用"g++ -std=c++11"进行编译):
#include <iostream>
#include <utility>
#include <type_traits>
#include <typeinfo>
#include <cxxabi.h>
using namespace std;
int main()
{
const auto M = 2;
const auto N = 2;
// allocate (no initializatoin)
auto array = new double[M][N];
// pollute the memory
array[0][0] = 2;
array[1][0] = 3;
array[0][1] = 4;
array[1][1] = 5;
// re-allocate, probably will fetch the same memory block (not portable)
delete[] array;
array = new double[M][N];
// show that memory is not initialized
for(int r = 0; r < M; r++)
{
for(int c = 0; c < N; c++)
cout << array[r][c] << " ";
cout << endl;
}
cout << endl;
delete[] array;
// the proper way to zero-initialize the array
array = new double[M][N]();
// show the memory is initialized
for(int r = 0; r < M; r++)
{
for(int c = 0; c < N; c++)
cout << array[r][c] << " ";
cout << endl;
}
int info;
cout << abi::__cxa_demangle(typeid(array).name(),0,0,&info) << endl;
return 0;
}
输出:
2 4
3 5
0 0
0 0
double (*) [2]
using arr2d = double(*)[2];
arr2d array = new double[M][2]; - Mohammad Alaggandouble (*)[M][N] 或 double(*)[][N],其中 M 和 N 是常量表达式。 - Fozi根据你提供的静态数组示例,我猜想你想要一个矩形数组而不是一个嵌套数组。你可以使用以下内容:
int *ary = new int[sizeX * sizeY];
那么您可以这样访问元素:
ary[y*sizeX + x]
别忘记在ary上使用delete[]。
在C++11及以上版本中,我建议使用三种通用技术:
所有答案都假设您想要统一的二维数组(而不是不规则的数组)。
使用std::array的std::array,然后使用new将其放在堆上:
// the alias helps cut down on the noise:
using grid = std::array<std::array<int, sizeX>, sizeY>;
grid * ary = new grid;
再次强调,这仅适用于在编译时已知维度大小的情况。
实现一个只在运行时才知道大小的二维数组的最佳方法是将其封装成一个类。该类将分配一个一维数组,然后重载operator []以提供第一维的索引。
这是因为在C++中,二维数组是按行主序排列的:
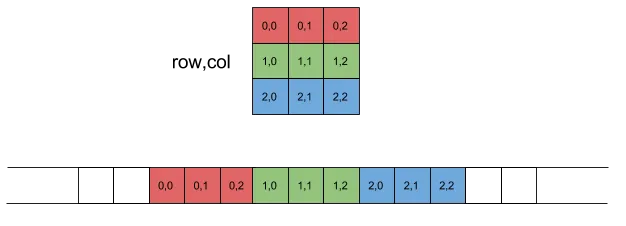
(摘自http://eli.thegreenplace.net/2015/memory-layout-of-multi-dimensional-arrays/)
连续的内存序列出于性能原因是很好的,而且也容易清理。下面是一个示例类,省略了许多有用的方法,但展示了基本思想:
#include <memory>
class Grid {
size_t _rows;
size_t _columns;
std::unique_ptr<int[]> data;
public:
Grid(size_t rows, size_t columns)
: _rows{rows},
_columns{columns},
data{std::make_unique<int[]>(rows * columns)} {}
size_t rows() const { return _rows; }
size_t columns() const { return _columns; }
int *operator[](size_t row) { return row * _columns + data.get(); }
int &operator()(size_t row, size_t column) {
return data[row * _columns + column];
}
}
因此,我们使用带有 std::make_unique<int[]>(rows * columns) 条目的数组。我们重载了 operator [],它将为我们索引行。它返回一个指向该行开头的 int *,然后可以像正常情况下一样对列进行取消引用。请注意,make_unique 首先在 C++14 中推出,但如果需要,您可以在 C++11 中使用 polyfill。
这些类型的结构通常也会重载 operator():
int &operator()(size_t row, size_t column) {
return data[row * _columns + column];
}
从技术上讲,我在这里没有使用new,但是从std::unique_ptr<int[]>移动到int *并使用new/delete是微不足道的。
对于C++23,有std::mdspan。该视图将内存的连续区域广义化为多维视图。例如,一个1x12的内存区域可以是4x3或2x3x2等,只要视图在底层内存区域上实际上是有意义的。以下是一个示例:
#include <mdspan>
#include <print>
#include <vector>
int main() {
std::vector v = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
// View data as contiguous memory representing 2 rows of 6
// ints each
auto ms2 = std::mdspan(v.data(), 2, 6);
// View the same data as a 3D array 2 x 3 x 2
auto ms3 = std::mdspan(v.data(), 2, 3, 2);
// write data using 2D view
for (size_t i = 0; i != ms2.extent(0); i++)
for (size_t j = 0; j != ms2.extent(1); j++)
ms2[i, j] = i * 1000 + j;
// read back using 3D view
for (size_t i = 0; i != ms3.extent(0); i++) {
std::println("slice @ i = {}", i);
for (size_t j = 0; j != ms3.extent(1); j++) {
for (size_t k = 0; k != ms3.extent(2); k++)
std::print("{} ", ms3[i, j, k]);
std::println("");
}
}
}
std::array的std::array:std::array<std::array<int, columns> rows>。 - Levi Morrisonusing grid = std::array<std::array<int, sizeX>, sizeY>; 在 sizeY 之前缺少逗号。 - Arash为什么不使用STL:vector?它很简单,而且你不需要删除向量。
int rows = 100;
int cols = 200;
vector< vector<int> > f(rows, vector<int>(cols));
f[rows - 1][cols - 1] = 0; // use it like arrays
您也可以对“arrays”进行初始化,只需给它一个默认值
const int DEFAULT = 1234;
vector< vector<int> > f(rows, vector<int>(cols, DEFAULT));
multi_array。它甚至包括一个multi_array_ref类,可以用来包装你自己的一维数组缓冲区。auto关键字。我很惊讶他们还没有尝试解决二维数组问题,特别是因为Boost已经展示了方法。 - Mark Ransom一个二维数组基本上是一个指针的一维数组,其中每个指针都指向一个一维数组,该数组将保存实际的数据。
这里N是行数,M是列数。
动态分配
int** ary = new int*[N];
for(int i = 0; i < N; i++)
ary[i] = new int[M];
填充
for(int i = 0; i < N; i++)
for(int j = 0; j < M; j++)
ary[i][j] = i;
打印
for(int i = 0; i < N; i++)
for(int j = 0; j < M; j++)
std::cout << ary[i][j] << "\n";
免费
for(int i = 0; i < N; i++)
delete [] ary[i];
delete [] ary;
这个问题困扰了我15年,所有提供的解决方案都没有令我满意。如何在内存中连续地创建动态多维数组?今天我终于找到了答案。使用以下代码,你可以轻松做到:
#include <iostream>
int main(int argc, char** argv)
{
if (argc != 3)
{
std::cerr << "You have to specify the two array dimensions" << std::endl;
return -1;
}
int sizeX, sizeY;
sizeX = std::stoi(argv[1]);
sizeY = std::stoi(argv[2]);
if (sizeX <= 0)
{
std::cerr << "Invalid dimension x" << std::endl;
return -1;
}
if (sizeY <= 0)
{
std::cerr << "Invalid dimension y" << std::endl;
return -1;
}
/******** Create a two dimensional dynamic array in continuous memory ******
*
* - Define the pointer holding the array
* - Allocate memory for the array (linear)
* - Allocate memory for the pointers inside the array
* - Assign the pointers inside the array the corresponding addresses
* in the linear array
**************************************************************************/
// The resulting array
unsigned int** array2d;
// Linear memory allocation
unsigned int* temp = new unsigned int[sizeX * sizeY];
// These are the important steps:
// Allocate the pointers inside the array,
// which will be used to index the linear memory
array2d = new unsigned int*[sizeY];
// Let the pointers inside the array point to the correct memory addresses
for (int i = 0; i < sizeY; ++i)
{
array2d[i] = (temp + i * sizeX);
}
// Fill the array with ascending numbers
for (int y = 0; y < sizeY; ++y)
{
for (int x = 0; x < sizeX; ++x)
{
array2d[y][x] = x + y * sizeX;
}
}
// Code for testing
// Print the addresses
for (int y = 0; y < sizeY; ++y)
{
for (int x = 0; x < sizeX; ++x)
{
std::cout << std::hex << &(array2d[y][x]) << ' ';
}
}
std::cout << "\n\n";
// Print the array
for (int y = 0; y < sizeY; ++y)
{
std::cout << std::hex << &(array2d[y][0]) << std::dec;
std::cout << ": ";
for (int x = 0; x < sizeX; ++x)
{
std::cout << array2d[y][x] << ' ';
}
std::cout << std::endl;
}
// Free memory
delete[] array2d[0];
delete[] array2d;
array2d = nullptr;
return 0;
}
当您使用值sizeX = 20和sizeY = 15调用程序时,输出将如下所示:
0x603010 0x603014 0x603018 0x60301c 0x603020 0x603024 0x603028 0x60302c 0x603030 0x603034 0x603038 0x60303c 0x603040 0x603044 0x603048 0x60304c 0x603050 0x603054 0x603058 0x60305c 0x603060 0x603064 0x603068 0x60306c 0x603070 0x603074 0x603078 0x60307c 0x603080 0x603084 0x603088 0x60308c 0x603090 0x603094 0x603098 0x60309c 0x6030a0 0x6030a4 0x6030a8 0x6030ac 0x6030b0 0x6030b4 0x6030b8 0x6030bc 0x6030c0 0x6030c4 0x6030c8 0x6030cc 0x6030d0 0x6030d4 0x6030d8 0x6030dc 0x6030e0 0x6030e4 0x6030e8 0x6030ec 0x6030f0 0x6030f4 0x6030f8 0x6030fc 0x603100 0x603104 0x603108 0x60310c 0x603110 0x603114 0x603118 0x60311c 0x603120 0x603124 0x603128 0x60312c 0x603130 0x603134 0x603138 0x60313c 0x603140 0x603144 0x603148 0x60314c 0x603150 0x603154 0x603158 0x60315c 0x603160 0x603164 0x603168 0x60316c 0x603170 0x603174 0x603178 0x60317c 0x603180 0x603184 0x603188 0x60318c 0x603190 0x603194 0x603198 0x60319c 0x6031a0 0x6031a4 0x6031a8 0x6031ac 0x6031b0 0x6031b4 0x6031b8 0x6031bc 0x6031c0 0x6031c4 0x6031c8 0x6031cc 0x6031d0 0x6031d4 0x6031d8 0x6031dc 0x6031e0 0x6031e4 0x6031e8 0x6031ec 0x6031f0 0x6031f4 0x6031f8 0x6031fc 0x603200 0x603204 0x603208 0x60320c 0x603210 0x603214 0x603218 0x60321c 0x603220 0x603224 0x603228 0x60322c 0x603230 0x603234 0x603238 0x60323c 0x603240 0x603244 0x603248 0x60324c 0x603250 0x603254 0x603258 0x60325c 0x603260 0x603264 0x603268 0x60326c 0x603270 0x603274 0x603278 0x60327c 0x603280 0x603284 0x603288 0x60328c 0x603290 0x603294 0x603298 0x60329c 0x6032a0 0x6032a4 0x6032a8 0x6032ac 0x6032b0 0x6032b4 0x6032b8 0x6032bc 0x6032c0 0x6032c4 0x6032c8 0x6032cc 0x6032d0 0x6032d4 0x6032d8 0x6032dc 0x6032e0 0x6032e4 0x6032e8 0x6032ec 0x6032f0 0x6032f4 0x6032f8 0x6032fc 0x603300 0x603304 0x603308 0x60330c 0x603310 0x603314 0x603318 0x60331c 0x603320 0x603324 0x603328 0x60332c 0x603330 0x603334 0x603338 0x60333c 0x603340 0x603344 0x603348 0x60334c 0x603350 0x603354 0x603358 0x60335c 0x603360 0x603364 0x603368 0x60336c 0x603370 0x603374 0x603378 0x60337c 0x603380 0x603384 0x603388 0x60338c 0x603390 0x603394 0x603398 0x60339c 0x6033a0 0x6033a4 0x6033a8 0x6033ac 0x6033b0 0x6033b4 0x6033b8 0x6033bc 0x6033c0 0x6033c4 0x6033c8 0x6033cc 0x6033d0 0x6033d4 0x6033d8 0x6033dc 0x6033e0 0x6033e4 0x6033e8 0x6033ec 0x6033f0 0x6033f4 0x6033f8 0x6033fc 0x603400 0x603404 0x603408 0x60340c 0x603410 0x603414 0x603418 0x60341c 0x603420 0x603424 0x603428 0x60342c 0x603430 0x603434 0x603438 0x60343c 0x603440 0x603444 0x603448 0x60344c 0x603450 0x603454 0x603458 0x60345c 0x603460 0x603464 0x603468 0x60346c 0x603470 0x603474 0x603478 0x60347c 0x603480 0x603484 0x603488 0x60348c 0x603490 0x603494 0x603498 0x60349c 0x6034a0 0x6034a4 0x6034a8 0x6034ac 0x6034b0 0x6034b4 0x6034b8 0x6034bc
0x603010: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
0x603060: 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39
0x6030b0: 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59
0x603100: 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79
0x603150: 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99
0x6031a0: 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119
0x6031f0: 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139
0x603240: 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159
0x603290: 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179
0x6032e0: 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199
0x603330: 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219
0x603380: 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239
0x6033d0: 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259
0x603420: 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279
0x603470: 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299
正如你所看到的,多维数组在内存中是连续的,没有两个内存地址重叠。即使是释放数组的例程也比标准的动态分配每个单独列(或行,取决于您如何看待数组)的内存的方式更简单。由于该数组基本上由两个线性数组组成,因此只有这两个数组需要被释放。
这种方法可以使用相同的概念扩展到超过两个维度。我这里不做详细介绍,但是当你理解其背后的思想时,这是一个简单的任务。
我希望这段代码能像它对我有用一样,对你也有所帮助。
array2d[i] = buffer + i * sizeX。因此,这在一定程度上有所帮助,但是在使用该数组的代码中,编译器无法仅递增指针以扫描数组。 - Peter Cordesmake_unique<int[]>(sizeX*sizeY)来设置连续存储空间,以及make_unique<int*[]>(sizeX)来设置指针的存储空间(应该像您展示的方式一样分配)。这样做可以避免在最后调用两次delete[]的要求。 - Ben Voigttemp吗?考虑到它的优势(在编译时具有未知维度的连续二维数组),我不确定我是否在意它是否悬挂。我不理解@PeterCordes所说的“额外的间接层”,它是什么?为什么要加括号, array2d[i] = (temp + i * sizeX); - KcFnMi