据我所知,一些版本控制系统存储版本之间的差异,因为有时候差异很小——源代码中的一行被更改或者在随后的版本中添加了注释。另一方面,Git为每个版本存储了压缩的“快照”。
如果只有一个小的更改(大文本文件中的一行),Git会如何处理?它会存储两个几乎相同的副本吗?这将是一种低效的空间利用,我想。
据我所知,一些版本控制系统存储版本之间的差异,因为有时候差异很小——源代码中的一行被更改或者在随后的版本中添加了注释。另一方面,Git为每个版本存储了压缩的“快照”。
如果只有一个小的更改(大文本文件中的一行),Git会如何处理?它会存储两个几乎相同的副本吗?这将是一种低效的空间利用,我想。
它存储两个几乎相同的副本吗?我认为这将是一种低效的空间利用方式。
是的,Git 在开始时确实这样做。当您进行提交时,Git 会在 .git/objects/ 树下创建一个(稍微压缩过的)源文件的复制品,名称基于内容的 SHA1(这些称为“loose”对象)。您可以查看这些文件,如果您对格式感到好奇,这样做是值得的。
需要记住的要点是 Git 是为了速度而构建的,并且并不非常关心存储库数据的大小。当 Git 想要获取旧版本以查看它时,它只需从 .git/objects/ 树中读取文件即可。没有应用增量,只是使用 zlib 解压缩(非常快速)的原始字节读取。
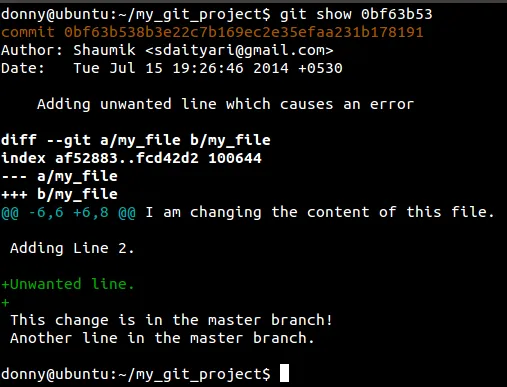
.git/objects/中的文件将包含许多源文件的副本,它们都略有不同。这就是“pack”文件发挥作用的地方。当您创建打包文件(自动或手动)时,Git会将所有文件对象收集在一起,并按照压缩良好的方式对它们进行排序,并使用多种不同的技术将它们压缩成一个打包文件。.git/objects/pack/),看看是否可以在那里找到。当Git找到正确的包文件时,它从包文件中提取对象,并应用任何算法(增量解析、解压缩等)来重建原始文件对象。Git的高级部分不关心包文件如何存储数据,这是责任分离的好处,简化了应用程序代码。git gc可以执行此操作。 - Lasse V. Karlsengit log and copy the SHA1 of the commitExecute git cat-file SHA1-of-commit and you will see something like this:
tree d7d68c5b2ecc58da225c953e35b0797a4805b844
author Lasse Vågsæther Karlsen <lassevagsaether.karlsen@visma.com> 1491986419 +0200
committer Lasse Vågsæther Karlsen <lassevagsaether.karlsen@visma.com> 1491986419 +0200
First copy
Now make a copy of the SHA1 id after tree, this is the object id of the tree object, then execute git cat-file SHA1-of-tree-object, and you will see something like this:
100644 blob 3b5d02884e6a17f20ed7938bf9e534f1bd0d195e Temp.7z
This tells you that the index contains 1 file (1 line), with the filename Temp.7z, and it tells you its SHA1 id. Copy this id.
git cat-file -p SHA1-of-blob and you will see the contents of the file you added.Git的存储模型并不神奇或复杂,但其中存在很多优化和抽象,以避免浪费空间、去重等问题。
Git使用补丁或“hunks”来进行操作。它计算引入的差异并将其存储在两个版本之间。
存储两个几乎相同的副本?我认为这将是一种低效的空间利用。
Git扫描您的代码(启发式)并仅存储差异。如果git在多个文件中找到相同的代码,则为类似的代码生成“hunk”,并在原始位置中存储指针。
简单来说,它比下面解释的要复杂得多,这样您就可以更容易地理解它。
一旦扫描了您的代码,git会搜索与上一个提交的更改,如果发现更改,则将旧更改拆分为“hunk”。
如果您在文件的中间添加了代码,则它将被拆分为3个“hunk”(顶部=旧代码,中间=新代码,底部=旧代码),现在您将有3个“hunk”。下次git扫描您的代码时,它将使用这3个“hunk”来搜索更改。
这样,git以非常高效的方式存储信息。
git add -p并选择s进行拆分。
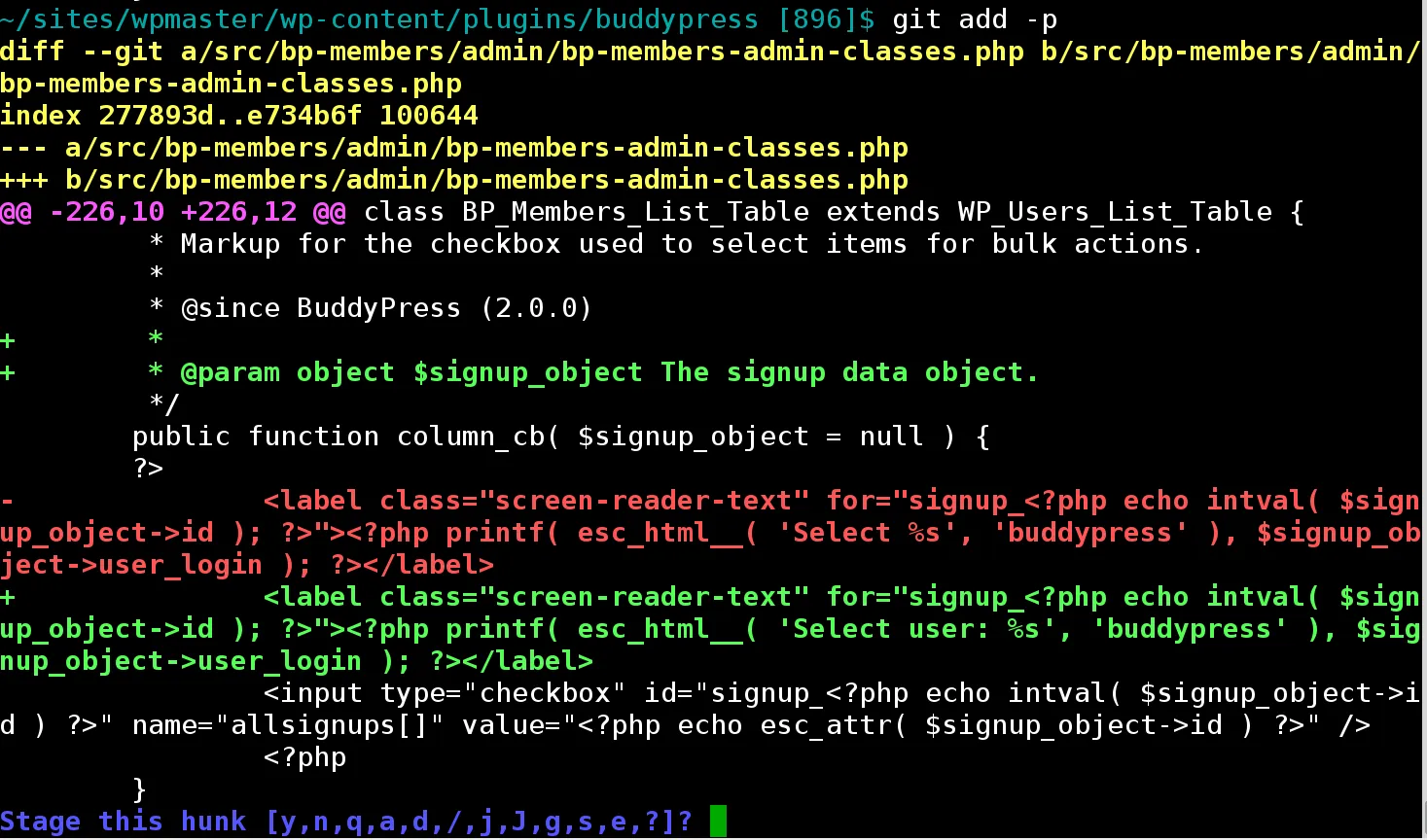
如上所述,hunk是一个diff术语,以下是一些相关信息。
hunk是与diff相关的术语,以下是git如何在可视化(补丁)中显示它:
该格式以与上下文格式相同的两行标题开头,除了原始文件前面有
---,新文件前面有+++。接下来是一个或多个更改块,其中包含文件中的行差异。
未更改的上下文行前面有一个空格字符,添加的行前面有一个加号,删除的行前面有一个减号。
https://github.com/mirage/ocaml-git/blob/master/doc/pack-heuristics.txt
git add -p 命令的输出,你看到的是一个格式化的补丁。如果你想要查看补丁本身,请在下一次提交时使用 git commit --verbose 命令,你将会看到精确的补丁。 - CodeWizardgit add -p 提供的用户界面与实际的磁盘存储格式无关。据我所知,你所描述的“Hunk 指针”实际上并未出现在 Git 中。因此,出于这些原因,我必须对你的回答进行投票反对。 - Greg Hewgillgit show,而应改用 git cat-file -p。这样可以避免输出被篡改,因为它不会尝试猜测您可能想要查看什么,而是显示实际的底层文件(虽然它会解压缩文件,但不会进行差异或类似操作)。 - Lasse V. Karlsengit blame显示的行来自另一个文件,则完全是git blame的结果,而不是以任何方式存储在仓库中。 - Lasse V. Karlsen