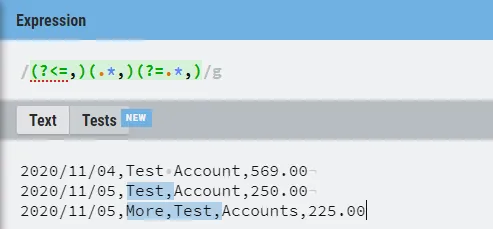
使用awk或sed在bash脚本中,我需要删除位于内部和外部分隔符之间的逗号分隔符。问题是错误的值最终出现在错误的列中,只有3列是期望的。
例如,我想把这个变成:
例如,我想把这个变成:
2020/11/04,Test Account,569.00
2020/11/05,Test,Account,250.00
2020/11/05,More,Test,Accounts,225.00
转化为:
2020/11/04,Test Account,569.00
2020/11/05,Test Account,250.00
2020/11/05,More Test Accounts,225.00
我尝试使用一些东西来测试正则表达式: 但是我找不到仅选择逗号以删除的解决方案。