我很好奇是否有任何迹象表明在使用sorted()函数时,作为key关键字参数,operator.itemgetter(0)和lambda x:x[0]哪个更好用。是否有已知的性能差异?另外,是否有PEP相关的偏好或指导?
operator.itemgetter或lambda
46
- Endophage
4
3个回答
47
itemgetter函数的性能略微更好:
>>> f1 = lambda: sorted(w, key=lambda x: x[1])
>>> f2 = lambda: sorted(w, key=itemgetter(1))
>>> timeit(f1)
21.33667682500527
>>> timeit(f2)
16.99106214600033
- michaelmeyer
3
3这里所测量的是 Lambda 函数的创建。要测量排序本身,应该使用
timeit(f1()) 和 timeit(f2())。或者我理解错了吗? - dojuba2如果
timeit.timeit的参数不是字符串,则会调用它。 - user4698348是啊,但是谁会用 Python 来写需要快速运行的程序呢? - CpILL
22
抛开速度问题不谈,它通常取决于你在哪里使用itemgetter或lambda函数,我个人认为itemgetter非常适合一次获取多个项目:例如,itemgetter(0, 4, 3, 9, 19, 20)将创建一个函数,返回传递给它的类似于列表对象中指定索引处项目的元组。要使用lambda实现这一点,则需要lambda x:x[0], x[4], x[3], x[9], x[19], x[20],这会显得更加笨重。(有些包如numpy具有高级索引功能,其工作方式与itemgetter()类似,但内置于正常括号表示法中。)
- JAB
1
1+1多次输入方面的卓越观点,无疑itemgetter是胜利者。 - Endophage
14
根据我的基准测试结果,在一个包含1000个元组的列表上,使用itemgetter方法比使用简单的lambda方法快近一倍。以下是我的代码:
根据我的基准测试结果,在一个包含一千个元组的列表上,使用itemgetter方法比使用简单的lambda方法快近一倍。以下是我的代码:
In [1]: a = list(range(1000))
In [2]: b = list(range(1000))
In [3]: import random
In [4]: random.shuffle(a)
In [5]: random.shuffle(b)
In [6]: c = list(zip(a, b))
In [7]: %timeit c.sort(key=lambda x: x[1])
81.4 µs ± 433 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
In [8]: random.shuffle(c)
In [9]: from operator import itemgetter
In [10]: %timeit c.sort(key=itemgetter(1))
47 µs ± 202 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
我还测试了这两种方法在不同列表大小下的性能(以微秒为单位的运行时间)。
+-----------+--------+------------+
| List size | lambda | itemgetter |
+-----------+--------+------------+
| 100 | 8.19 | 5.09 |
+-----------+--------+------------+
| 1000 | 81.4 | 47 |
+-----------+--------+------------+
| 10000 | 855 | 498 |
+-----------+--------+------------+
| 100000 | 14600 | 10100 |
+-----------+--------+------------+
| 1000000 | 172000 | 131000 |
+-----------+--------+------------+
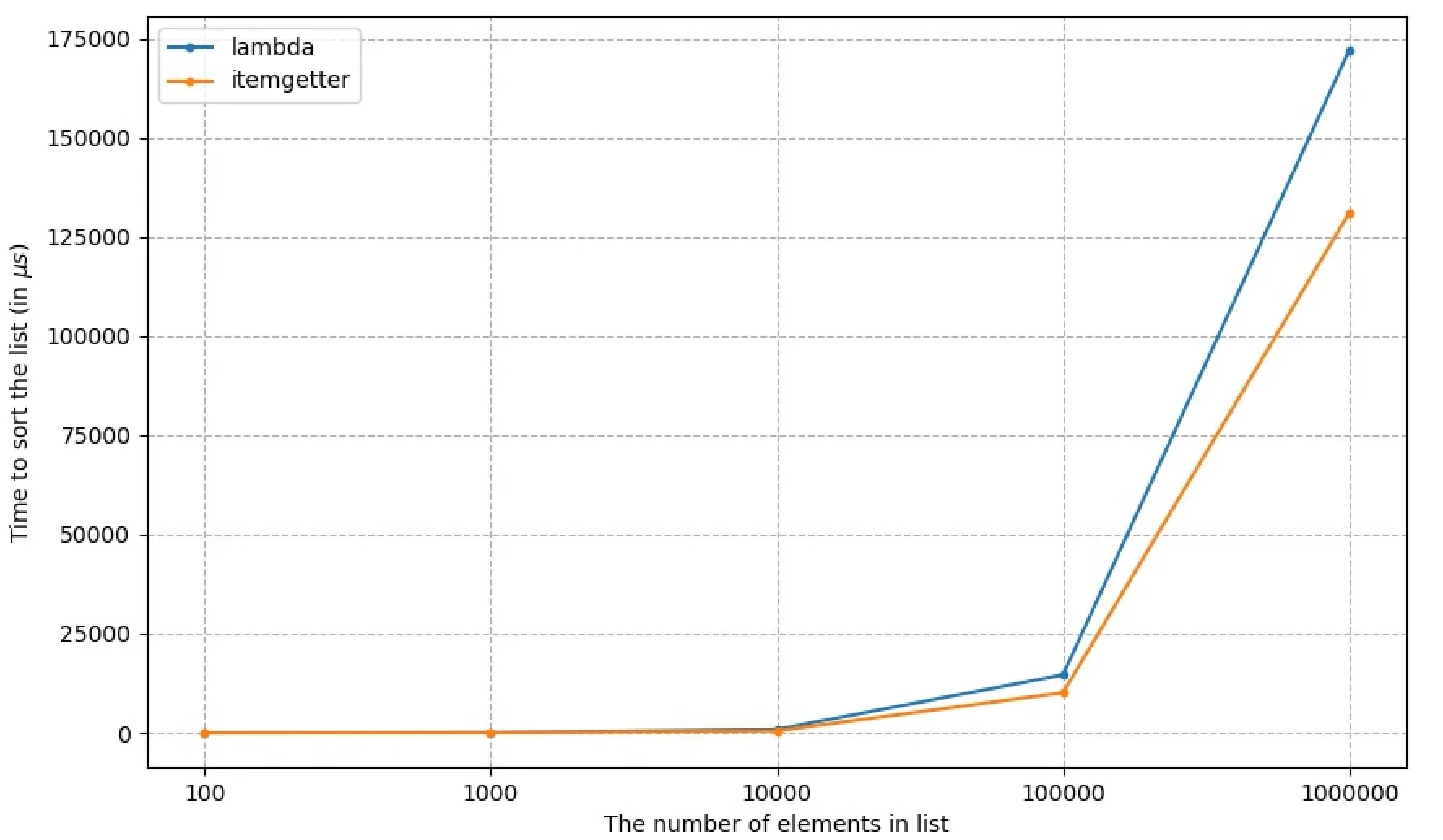
(生成上述图片的代码可以在这里找到)
与简洁地从列表中选择多个元素相结合,itemgetter 显然是在 sort 方法中使用的最佳选择。
- jdhao
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 20 使用 operator.itemgetter 对字典进行排序
- 7 为什么在multiprocessing.Pool中不能使用operator.itemgetter?
- 4 如何读取或解释Lambda中的Lambda
- 7 如何在使用 operator.itemgetter 对字典列表进行排序时忽略 None 值?
- 3 如何使用operator.itemgetter()对csv文件进行排序
- 4 使用operator.itemgetter()作为排序键时,是否有一种方法可以转换值?
- 3 AWS Lambda, Python:如何从Lambda调用Shell脚本或Linux命令
- 126 operator.itemgetter()和sort()如何工作?
- 3 使用operator.itemgetter函数的apply和applymap方法行为不一致
- 43 为什么我应该使用operator.itemgetter(x)而不是[x]?
operator.itemgetter(0)。 - oleg