我不确定是否以最佳方式解决了类似问题,但在我的某个项目中,为了解决类似问题,我编写了一些实用函数来处理它。您可以在此处查看这些函数
拆分背后的逻辑是,每当存在只包含NA的行或列时,就会在该行或列上创建拆分。并且这个过程将进行一定次数。
无论如何,如果您加载了我编写的所有函数,您可以使用以下代码:
读取数据
library(tidyverse)
table_raw<- readxl::read_excel("example.xlsx",col_names = FALSE,col_types = "text")
显示数据形状
display_table_shape(table_raw)

将数据拆分为单独的数据框。
split_table <- table_raw %>%
split_df(complexity = 2)
在将原始数据框分割后,您可以使用for循环或map函数进行更多处理。
数据清洗
map(split_table, function(df){
df <- df[-1,]
set_1row_colname(df) %>%
mutate_all(as.numeric)
})
结果
[[1]]
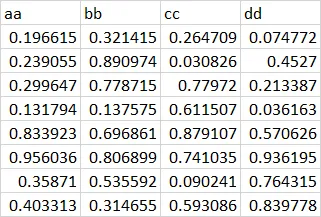
aa bb cc dd
<dbl> <dbl> <dbl> <dbl>
1 0.197 0.321 0.265 0.0748
2 0.239 0.891 0.0308 0.453
3 0.300 0.779 0.780 0.213
4 0.132 0.138 0.612 0.0362
5 0.834 0.697 0.879 0.571
6 0.956 0.807 0.741 0.936
7 0.359 0.536 0.0902 0.764
8 0.403 0.315 0.593 0.840
[[2]]
aa bb cc dd
<dbl> <dbl> <dbl> <dbl>
1 0.136 0.347 0.603 0.542
2 0.790 0.672 0.0808 0.795
3 0.589 0.338 0.837 0.00968
4 0.513 0.766 0.553 0.189
[[3]]
aa bb cc dd
<dbl> <dbl> <dbl> <dbl>
1 0.995 0.105 0.106 0.530
2 0.372 0.306 0.190 0.609
3 0.508 0.987 0.585 0.233
4 0.0800 0.851 0.215 0.761
5 0.471 0.603 0.740 0.106
6 0.395 0.0808 0.571 0.266
7 0.908 0.739 0.245 0.141
8 0.534 0.313 0.663 0.824
[[4]]
aa bb cc dd
<dbl> <dbl> <dbl> <dbl>
1 0.225 0.993 0.0382 0.412
2 0.280 0.202 0.823 0.664
3 0.423 0.616 0.377 0.857
4 0.289 0.298 0.0418 0.410
5 0.919 0.932 0.882 0.668
6 0.568 0.561 0.600 0.832
7 0.341 0.210 0.351 0.0863
8 0.757 0.962 0.484 0.677
9 0.275 0.0845 0.824 0.571
10 0.187 0.512 0.884 0.612
11 0.706 0.311 0.00610 0.463
12 0.906 0.411 0.215 0.377
13 0.629 0.317 0.0975 0.312
14 0.144 0.644 0.906 0.353
你需要加载的函数
vec_rle <- function(v){
temp <- rle(v)
out <- temp$values
names(out) <- temp$lengths
return(out)
}
make_df_index <- function(v){
table_rle <- vec_rle(v)
divide_points <- c(0,cumsum(names(table_rle)))
table_index <- map2((divide_points + 1)[1:length(divide_points)-1],
divide_points[2:length(divide_points)],
~.x:.y)
return(table_index[table_rle])
}
split_direction <- function(df,direction = "col"){
if(direction == "col"){
col_has_data <- unname(map_lgl(df,~!all(is.na(.x))))
df_mapping <- make_df_index(col_has_data)
out <- map(df_mapping,~df[,.x])
} else if(direction == "row"){
row_has_data <- df %>%
mutate_all(~!is.na(.x)) %>%
as.matrix() %>%
apply(1,any)
df_mapping <- make_df_index(row_has_data)
out <- map(df_mapping,~df[.x,])
}
return(out)
}
split_df <- function(df,showWarnig = TRUE,complexity = 1){
if(showWarnig){
warning("Please don't use first row as column names.")
}
out <- split_direction(df,"col")
for(i in 1 :complexity){
out <- out %>%
map(~split_direction(.x,"row")) %>%
flatten() %>%
map(~split_direction(.x,"col")) %>%
flatten()
}
return(out)
}
display_table_shape <- function(df){
colnames(df) <- 1:ncol(df)
out <- df %>%
map_df(~as.numeric(!is.na(.x))) %>%
gather(key = "x",value = "value") %>%
mutate(x = as.numeric(x)) %>%
group_by(x) %>%
mutate(y = -row_number()) %>%
ungroup() %>%
filter(value == 1) %>%
ggplot(aes(x = x, y = y,fill = value)) +
geom_tile(fill = "skyblue3") +
scale_x_continuous(position = "top") +
theme_void() +
theme(legend.position="none",
panel.border = element_rect(colour = "black", fill=NA, size=2))
return(out)
}
set_1row_colname <- function(df){
colnames(df) <- as.character(df[1,])
out <- df[-1,]
return(out)
}