使用 PostgreSQL 版本 > 10 时,使用内置的 generate_series 函数生成日期序列时出现了问题。实际上,它不能正确地处理每月的“日期”。
我有很多不同的频率(由用户提供),需要在给定的开始和结束日期之间计算。开始日期可以是任何日期,因此可以是每个月的任何一天。当有像“每月”这样的频率与“2018-01-31”或“2018-01-30”这样的起始日期组合时,就会出现问题,如下面的输出所示。
我创建了一个解决方案,并希望在这里发布,让其他人使用,因为我找不到其他解决方案。
然而,在一些测试之后,我发现我的解决方案在处理(荒谬的)大日期范围时与内置的 generate_series 相比性能不同。有没有人知道如何改进这个问题?
简而言之,尽可能避免循环,因为它们会影响性能,请向下滚动以获取改进的实现。
内置输出:
@eurotrash提供的实现平均需要80毫秒,我认为是由于两次调用
我有很多不同的频率(由用户提供),需要在给定的开始和结束日期之间计算。开始日期可以是任何日期,因此可以是每个月的任何一天。当有像“每月”这样的频率与“2018-01-31”或“2018-01-30”这样的起始日期组合时,就会出现问题,如下面的输出所示。
我创建了一个解决方案,并希望在这里发布,让其他人使用,因为我找不到其他解决方案。
然而,在一些测试之后,我发现我的解决方案在处理(荒谬的)大日期范围时与内置的 generate_series 相比性能不同。有没有人知道如何改进这个问题?
简而言之,尽可能避免循环,因为它们会影响性能,请向下滚动以获取改进的实现。
内置输出:
select generate_series(date '2018-01-31',
date '2018-05-31',
interval '1 month')::date
as frequency;
生成:
frequency
------------
2018-01-31
2018-02-28
2018-03-28
2018-04-28
2018-05-28
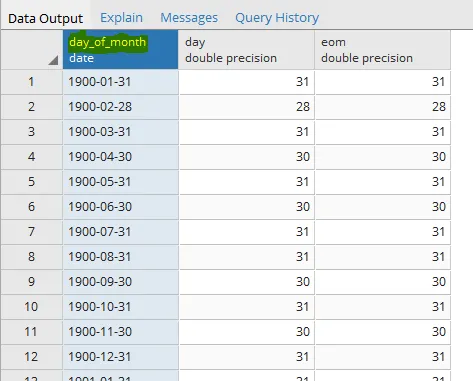
从输出结果可以看出,月份中的日期没有被尊重,而是被截断为沿途遇到的最小日期,例如在这种情况下:由于2月份的缘故,28天是最小的日期。
期望的输出
由于这个问题,我创建了一个自定义函数:
create or replace function generate_date_series(
starts_on date,
ends_on date,
frequency interval)
returns setof date as $$
declare
interval_on date := starts_on;
count int := 1;
begin
while interval_on <= ends_on loop
return next interval_on;
interval_on := starts_on + (count * frequency);
count := count + 1;
end loop;
return;
end;
$$ language plpgsql immutable;
select generate_date_series(date '2018-01-31',
date '2018-05-31',
interval '1 month')
as frequency;
生成:
frequency
------------
2018-01-31
2018-02-28
2018-03-31
2018-04-30
2018-05-31
性能比较
无论提供什么日期范围,内置的generate_series平均性能为2毫秒:
select generate_series(date '1900-01-01',
date '10000-5-31',
interval '1 month')::date
as frequency;
针对自定义函数generate_date_series,其平均性能为120毫秒,适用于以下情况:
select generate_date_series(date '1900-01-01',
date '10000-5-31',
interval '1 month')::date
as frequency;
问题
实际上,这种范围永远不会发生,因此这不是一个问题。对于大多数查询,自定义的generate_date_series将获得相同的性能。不过,我想知道是什么原因导致了差异。
为什么内置函数能够获得平均2ms的恒定性能,无论提供什么范围?
是否有更好的方法来实现generate_date_series,并且与内置的generate_series一样具有良好性能?
没有循环的改进实现
(源自@eurotrash的答案)
create or replace function generate_date_series(
starts_on date,
ends_on date,
frequency interval)
returns setof date as $$
select (starts_on + (frequency * count))::date
from (
select (row_number() over ()) - 1 as count
from generate_series(starts_on, ends_on, frequency)
) series
$$ language sql immutable;
通过改进实现,generate_date_series 函数的性能平均为45毫秒,适用于以下情况:
select generate_date_series(date '1900-01-01',
date '10000-5-31',
interval '1 month')::date
as frequency;
@eurotrash提供的实现平均需要80毫秒,我认为是由于两次调用
generate_series函数造成的。
generate_series的双重调用确实让我感到困扰,所以我修改了您的实现方式,以消除其中一个调用。我扩展了我的问题,包括这个实现方式。 - chvndb