我正在尝试基于数字特征和文本特征来预测社交网络帖子的点赞数。现在我有一个包含必需特征的数据框,但是我不知道该如何处理帖子的文本数据。我应该将其向量化/采取其他措施以获得适当的训练矩阵吗?我打算使用sklearn中的LinearSVC进行分析。
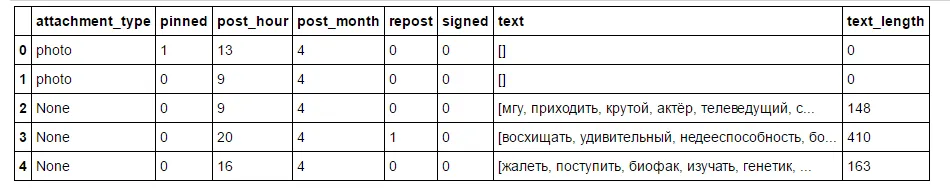
我正在尝试基于数字特征和文本特征来预测社交网络帖子的点赞数。现在我有一个包含必需特征的数据框,但是我不知道该如何处理帖子的文本数据。我应该将其向量化/采取其他措施以获得适当的训练矩阵吗?我打算使用sklearn中的LinearSVC进行分析。
有很多不同的方法可以将文本特征转换为数字特征。
其中最常见的方法之一是词袋模型。您可以将文本转换为一个数组,其中包含每个单词的出现次数。
如果您正在使用scikit-learn,则建议您阅读他们的文本特征提取用户指南。
此外,还可以查看NLTK工具包,以了解更复杂的处理文本数据的方法。