我有一个包含“直引号”(普通的ASCII)的文件,并且我想将它们转换为真正的引号符号字符(“卷曲”的引号,U+2018到U+201D)。由于从两个不同的引号字符转换为一个字符本身就是有损失的,显然没有办法自动执行此转换;尽管如此,我仍然认为一些启发式算法将涵盖大部分情况。因此,计划编写一个脚本(在Emacs中),执行以下操作:对于每个直引号字符,
- 如果可能,猜测使用哪个卷曲引号字符
- 要求用户(即我)确认或进行选择
- 如果双引号位于行首,则猜测其为开口引号。
- 如果双引号位于行末,则猜测为闭合引号。
- 如果双引号前面有空格,则猜测为开口引号。
- 如果双引号后面有空格,则猜测为闭合引号。
- 如果双引号不符合上述任何一种类别,则猜测它是最近使用的另一种双引号类型的“相反”。
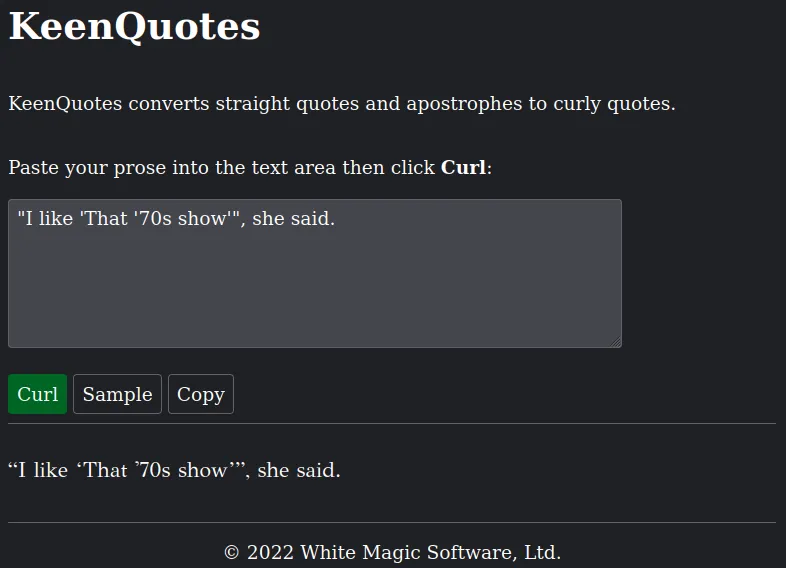
' 可能既是开头引号、结尾引号,或者撇号,我们需要保留撇号(不应该写成“mustn’t”)。一些和上面相同的规则适用,但有可能撇号在单词(或行)的开头,虽然这种情况比过去少了。我想不出规则来处理类似 ["I like 'That '70s show'", she said] 这样的片段。它可能需要查看不止相邻字符,并计算引号之间的距离,例如……
还有更多想法吗?如果没有覆盖所有可能的情况也没关系,目标是尽可能智能,但不要过度。:-)
编辑:还有一些可能值得考虑的事情(或可能与此无关,不确定):
- 引号可能不总是成对出现:对于单引号,如上所述,很明显为什么。但即使对于双引号,当引语延伸到多个段落时,通常的印刷惯例(不要问我为什么)是在每个段落开头加上引号,即使它在前一个段落中没有关闭。因此,简单地保持在两种状态之间交替的状态机将无法起作用!
- 嵌套引用(在上面的“我喜欢‘那个‘70年代秀’”示例中提到):这可能会使任一类型的引用不在前面或后面跟随空格。
- 英式/美式标点风格:逗号是在引号内还是外面?
- 许多文字处理器(例如Microsoft Word)已经执行了某种类似于此的转换。虽然它们并不完美,而且经常很烦人,但学习它们的工作方式可能是有益的...