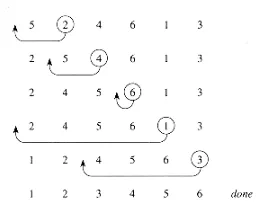
首先,这是我的希尔排序代码(使用Java):
public char[] shellSort(char[] chars) {
int n = chars.length;
int increment = n / 2;
while(increment > 0) {
int last = increment;
while(last < n) {
int current = last - increment;
while(current >= 0) {
if(chars[current] > chars[current + increment]) {
//swap
char tmp = chars[current];
chars[current] = chars[current + increment];
chars[current + increment] = tmp;
current -= increment;
}
else { break; }
}
last++;
}
increment /= 2;
}
return chars;
}
这是一个正确的希尔排序实现吗(暂时忘记最有效的间隔序列,例如1,3,7,21...)?我问这个问题是因为我听说希尔排序的最佳情况时间复杂度为O(n)。(参见http://en.wikipedia.org/wiki/Sorting_algorithm)。但我认为我的代码无法实现这种效率水平。如果我向其中添加启发式算法,那么可以,但现在不行。
话虽如此,我的主要问题是 - 我很难计算出我的希尔排序实现的大O时间复杂度。我确定最外层循环为O(log n),中间循环为O(n),内部循环也为O(n),但我意识到内部两个循环实际上不会是O(n) - 它们会远远小于这个值 - 应该是什么呢?因为显然,这种算法的运行效率比O((log n) n^2)要高得多。
非常感谢任何指导,因为我很迷茫!:P