- https://devtalk.nvidia.com/default/topic/1014009/try-to-use-lock-and-unlock-in-cuda/
- Cuda Mutex,为什么会死锁?
- 如何在cuda中实现关键部分?
- 在CUDA中实现临界区
- https://wlandau.github.io/gpu/lectures/cudac-atomics/cudac-atomics.pdf。
- LOCK:等待将锁的原子值从0更改为1
- 执行一些关键操作
- UNLOCK:通过将其值设置为0来释放锁
如何实现步骤1?
一些答案建议使用
atomicCAS,而另一些则使用atomicExch。两者都是等效的吗?while (0 != (atomicCAS(&lock, 0, 1))) {}
while (atomicExch(&lock, 1) != 0) {}
如何正确实现第三步?
几乎所有的资料都建议使用atomicExch:
atomicExch(&lock, 0);
有一位用户提出了一个替代方案(在CUDA中实现关键部分),这个方案也是有意义的,但对他来说并不起作用(所以在CUDA中可能会导致未定义行为):
lock = 0;
在CPU上一般的自旋锁似乎是有效的,可以参考这里:https://dev59.com/h1rUa4cB1Zd3GeqPghzr#7007893。为什么我们不能在CUDA中使用它呢?
在第二步中,我们必须使用内存屏障和volatile限定符进行内存访问吗?
CUDA关于原子操作的文档(https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#atomic-functions)说明它们不保证顺序约束:
原子函数不作为内存屏障,并且不对内存操作施加同步或顺序约束
这是否意味着我们必须在临界区(2)的末尾使用内存屏障,以确保临界区(2)中的更改在解锁(3)之前对其他线程可见?
CUDA是否保证其他线程将看到一个线程在步骤(1)和(3)中使用原子操作所做的更改?
这对于内存屏障来说是不正确的(https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#memory-fence-functions):
内存屏障函数只影响线程的内存操作顺序;它们不能确保这些内存操作对其他线程可见(就像__syncthreads()对块内线程可见一样(请参阅同步函数))。
因此,原子操作也可能不正确。如果是这样,所有CUDA中的自旋锁实现都依赖于未定义行为。
如何在存在warp分歧的情况下实现可靠的自旋锁?
现在,假设我们已经回答了上面所有问题,让我们消除我们没有warp分歧的假设。在这种情况下,是否可以实现自旋锁?
主要问题(死锁)在https://wlandau.github.io/gpu/lectures/cudac-atomics/cudac-atomics.pdf的第30页中表示: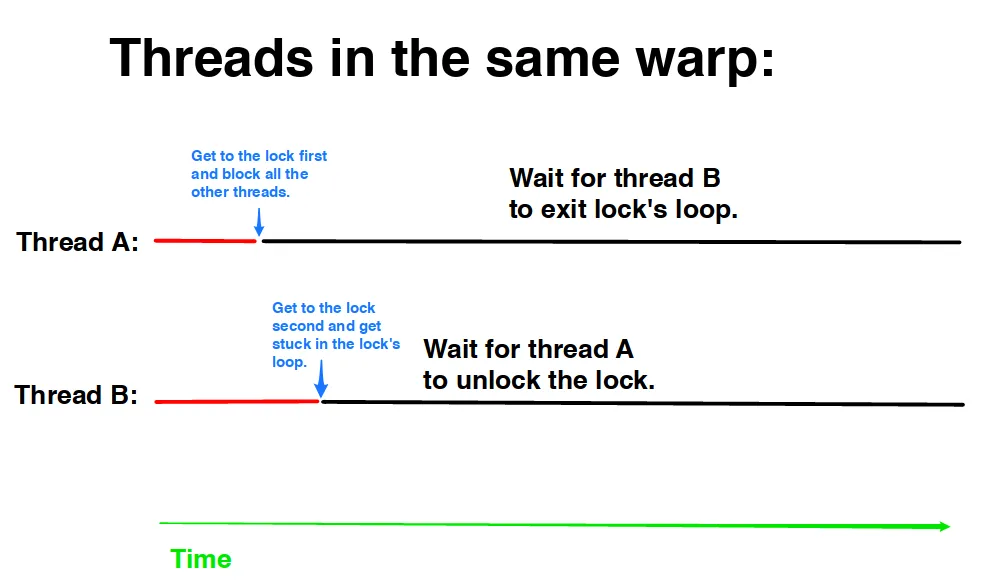
在步骤(1)中,替换while循环为if,并像Thread/warp local lock in cuda或CUDA, mutex and atomicCAS()中所建议的那样将所有3个步骤封装在单个while循环中,这是唯一的选择吗?