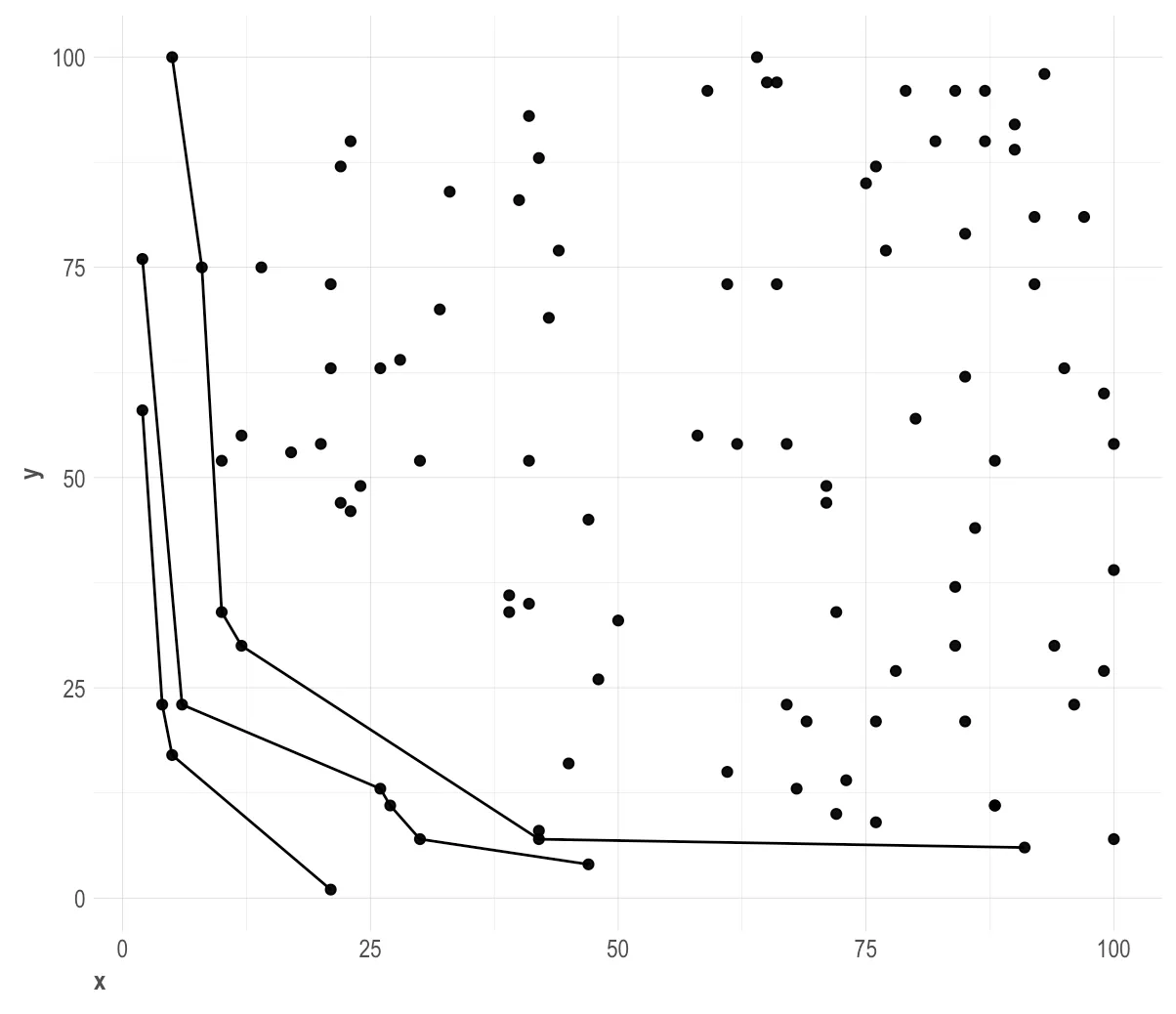
我正在尝试在R中计算帕累托前沿(http://en.wikipedia.org/wiki/Pareto_efficiency),并且能够完成,但是效率不高。特别是当点对数增加时,计算速度显著减慢。
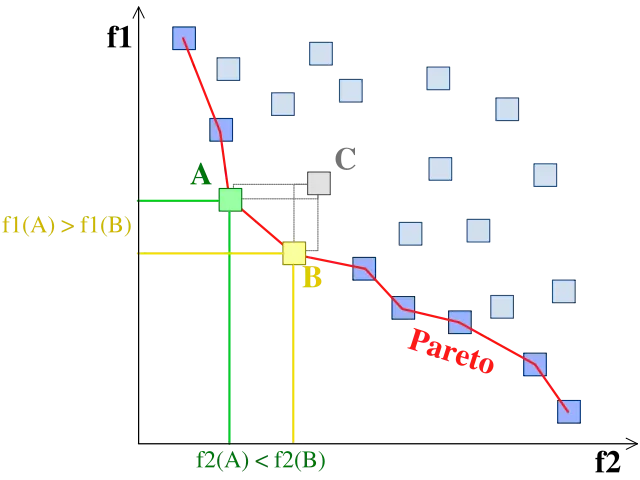
为了说明这一点,这里是维基百科上的一张图片:
以下是我的代码,虽然可行但对于大型数据集非常低效:
#Example Data that actually runs quickly
x = runif(10000)
y = runif(10000)
pareto = 1:length(x)
for(i in 1:length(x)){
cond1 = y[i]!=min(y[which(x==x[i])])
cond2 = x[i]!=min(x[which(y==y[i])])
for(n in 1:length(x)){
if((x[i]>x[n] & y[i]>y[n]) | (x[i]==x[n] & cond1) | (y[i]==y[n] & cond2)){
pareto[i] = NA
break
}
}
}
#All points not on the red line should be marks as NA in the pareto variable
慢速计算明显来自于计算
(x[i]==x[n] & cond1) | (y[i]==y[n] & cond2) 的点,但我找不到解决方法或更好的布尔表达式来捕获我想要的所有内容。非常感谢任何建议!