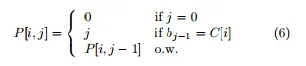阅读并研究了该论文后,我可以说
C应该是一个数组,保存字符串的字母表,其中字母表大小(因此
C的大小)为
l。
然而,从您的问题看来,我感觉需要深入探讨一下,因为看起来您还没有完全理解全貌。那么
P[i,j]是什么,为什么需要它呢?答案是您不
真正需要它,但这是一种优雅的优化。在第3页,在
Theorem 1之前稍微说了一下:
引用:
[...]当第k步时,j-k = 0或a(i) = b(j-k)。假设过程在第k步停止,k必须是使a(i) = b(j-k)或j-k = 0的最小数字。
式(3)中的递归关系等同于式(2),但根本区别在于式(2)会递归扩展,而对于式(3),只要您知道k,就不会有递归调用。换句话说,(3)不会递归地扩展的魔力是您以某种方式知道递归在(2)上将停止的位置,因此您立即查看该单元格,而不是以递归方式接近它。
那么,好的,那您如何找到
k的值呢?由于k是(2)达到基本情况的位置,因此可以看出k是您必须“回退”B的列数,直到您要么超出范围(即第一列填充为0的情况),要么在B中找到一个匹配A中字符的字符(这对应于(2)中的基本情况条件)。请记住,您将匹配字符
a(i-1),其中
i是当前行。
因此,您真正想要的是找到在
j之前的
B中最后一个出现字符
a(i-1)的位置。如果在
j之前没有这样的字符出现在
B中,则相当于在(2)中达到
i = 0或j-1 = 0的情况;否则,就相当于在(2)中达到
a(i) = b(j-1)的情况。
让我们来看一个例子:
考虑算法正在计算i = 2和j = 3的值(行和列用灰色突出显示)。想象一下,算法正在处理黑色突出显示的单元格,并应用(2)来确定S [2,2]的值(在黑色单元格左侧的位置)。通过应用(2),它将从查看a(2)和b(2)开始。a(2)是C,b(2)是G,因此没有匹配项(这与原始的著名算法相同)。现在,算法想要找到S [2,2]的值,因为需要计算S [2,3](我们所在的位置)。尚未知道S [2,2]的值,但是该论文表明可以确定该值而无需引用具有i = 2的行。在(2)中,选择第三种情况:S [2,2] = max(S [1,2],S [2,1])。请注意,如果您愿意,所有这个公式所做的就是查看计算S [2,2]可能使用的位置。因此,换句话说:我们正在计算S [2,3],我们需要S [2,2],我们还不知道它,因此我们会回到表上,以几乎与原始非并行算法相同的方式查看S [2,2]的值。
何时才能停止呢?在此示例中,当我们在当前列上找到字母C(这是我们的a(i))在第二个T(当前列上的字母)之前或达到列0时,它将停止。因为在T之前没有C,所以我们到达了列0。另一个例子:
在这里,(2)将停止,并且j-1 = 5,因为那是TGTTCGACA中最后出现C的位置。因此,当j-1 = 5时,递归达到基本情况a(i)= b(j-1)。
有了这个想法,我们可以看到一种快捷方式:如果您能够知道k的数量,使得j-1-k在(2)中是一个基本情况,那么您就不必通过得分表来找到基本情况。
这就是
P[i,j]的整个思想。
P 是一个表格,在左侧垂直地排列整个字母表;字符串
B再次水平地放置在上方。该表格作为预处理步骤的一部分进行计算,它将精确地告诉您需要提前了解的内容:对于
B中的每个位置
j,它��对于
C(字母表)中的每个字符
C[i],在
j之前
B中找到
C[i]的最后位置是什么(请注意,索引
i用于索引
C,即字母表,而不是字符串
A。也许作者应该使用另一个索引变量来避免混淆)。
因此,您可以将条目P[i,j]的语义视为以下行:“在位置j之前,我看到C[i]的B中的最后位置”。例如,如果您的字母表是sigma = {A, E, I, O, U},并且B = "AOOIUEI",那么P`如下:
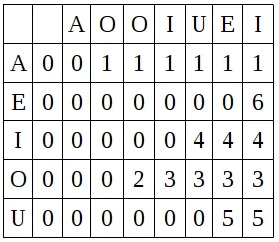
花些时间理解这张表。注意O的行。记住:该行列出了B中每个位置最后一个已知“O”的位置。仅当j = 3时,我们才会有一个不为零的值(它是2),因为这是在AOOIUEI中第一个O之后的位置。此条目表示,在j = 3之前,在B中看到O的最后位置是位置2(确实,B[2]是一个O,即跟随A的那个)。请注意,在同一行中,对于j = 4,我们具有值3,因为现在O的最后位置是与之相应的B中的第二个O(由于没有更多O存在,所以其余的行将为3)。
回想一下,构建P是必要的预处理步骤,如果您想轻松找到使方程式(2)的递归停止的k值。现在应该明白,P[i,j]是(3)中您要寻找的k值。使用P,您可以在O(1)的时间内确定该值。
因此,在(6)中,
C [i]是字母表中的一个字母-我们当前正在考虑的字母。在上面的示例中,
C = [A,E,I,O,U],
C [1] = A,
C [2] = E等。在等式(7)中,
c是
C中
a(i)(当前正在考虑的字符串
A的当前字母)所在的位置。这是有意义的:毕竟,在构建得分表位置
S [i,j]时,我们想使用
P找到
k的值-我们想知道最后一次看到
a(i)在
j之前在
B中的位置。我们通过读取
P [index_of(a(i)),j]来实现这一点。
好的,现在您了解了
P的用途,让我们看看您的实现情况。
关于您的特定情况
在论文中,
P显示为列出整个字母表的表格。遍历字母表是一个很好的主意,因为该算法的典型用途是生物信息学,其中字母表比字符串
A小得多,使得遍历字母表更加便宜。
由于您的字符串是对象序列,
因此您的C将是所有可能对象的集合,因此您必须使用所有可能对象实例(当然是无意义的)构建表格
P。与您的字符串大小相比,这绝对是字母表尺寸巨大的情况。但是,请注意,您只会在与
A中的字母对应的那些行中索引
P:任何不在
A中的字母
C [i]的
P中的行都是无用的,并且永远不会使用。
这使您的生活更轻松,因为它意味着您可以使用字符串
A而不是使用每个可能对象的字母表来构建
P。
再举一个例子:如果您的字母表是
AEIOU,
A是
EEI,
B是
AOOIUEI,则您仅会在
E和
I的行中索引
P,因此您在
P中只需要这些内容:
这很有效,因为在式(7)中,
P[c,j]是
P中字符
c的条目,而
c是
a(i)的索引。换句话说:
C[c]总是属于
A,因此为了情况下
A的大小远小于
C的大小的情况,构建
A的字符的
P比使用整个字母表更有意义。
现在你需要做的就是将同样的原则应用于你所处理的任何对象。
我真的不知道该如何更好地解释它。这可能会有点密集。确保重读,直到你真正理解它-我的意思是每一个细节。在考虑实现之前,你必须掌握这个技术。
注:你说你正在寻找可信和/或官方来源。我只是另一个计算机科学专业的学生,因此并非官方来源,但我认为我可以被认为是“可信”的。我曾经学过这个问题,也知道这个主题。祝你编程愉快!