有人能解释一下为什么这个方法有效吗?
char c = '9';
int x = (int)(c - '0');
为什么从一个字符的ASCII码中减去'0'可以得到该字符所代表的数字?
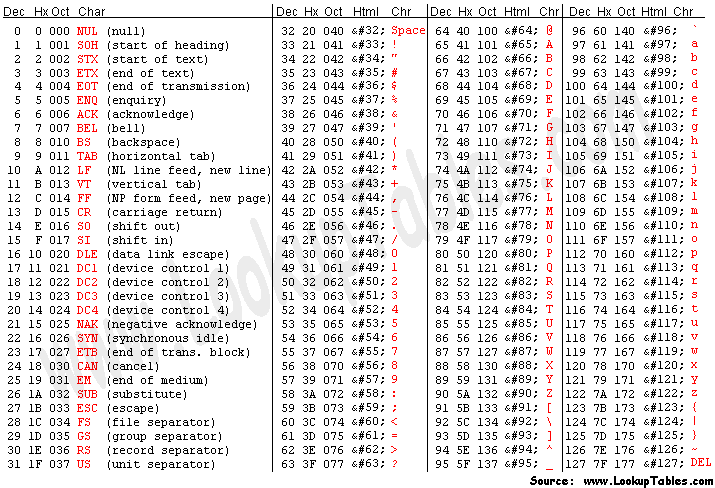
'0' => 48
'1' => 49
'9' => 57.
结果是:('9' - '0') = (57 − 48) = 9
'0' => 240,但是 '9'-'0' 仍然等于 9。 - Bo Persson'9'-'0'是正确的做法,而应避免使用'9' - 48。我们可以始终期望字符0到9按升序设置,但它们的实际值可能会有所不同。” - Jeanchar是一种整数类型,就像int和它的派生类一样。一个char类型的对象有一些数值。你在字符字面量中输入的字符(比如'0')和char对象所具有的数值之间的映射取决于该字符在执行字符集中的编码:
C++11 §2.14.3:
包含单个可在执行字符集中表示的c-char的普通字符字面量具有类型
char,其值等于执行字符集中c-char的编码的数值。
C99 §6.4.4.4:
整数字符常量是由一个或多个多字节字符组成的序列,用单引号括起来,例如
'x'。[...]
整数字符常量的类型是
int。
请注意,int可以转换为char。
执行字符集的选择取决于实现。往往情况下,选择与ASCII兼容的字符集,因此其他答案中发布的表格具有适当的值。然而,字符集不需要与ASCII兼容。但是,有一些限制。其中一个限制如下(C++11 §2.3,C99 §5.2.1):
a b c d e f g h i j k l m n o p q r s t u v w x y z A B C D E F G H I J K L M N O P Q R S T U V W X Y Z 0 1 2 3 4 5 6 7 8 9 _ { } [ ] # ( ) < > % : ; . ? * + - / ^ & | ~ ! = , \ " ’[...]
In both the source and execution basic character sets, the value of each character after 0 in the above list of decimal digits shall be one greater than the value of the previous.
这意味着无论字符'0'具有什么值,字符'1'的值比'0'多一,字符'2'的值比'1'多一,以此类推。数字字符具有连续的值。您可以总结映射如下:
Character: 0 1 2 3 4 5 6 7 8 9
Corresponding value: X X+1 X+2 X+3 X+4 X+5 X+6 X+7 X+8 X+9
所有数字字符都与'0'的值相差一定的距离。
这意味着,如果你有一个字符,比如说'9',并从它减去'0',你得到了在执行字符集中'9'和'0'之间的"距离"。由于它们是连续的,那么这个距离将为9。
int。 - pmg'a' .. 'z'是连续的,实际上在EBCDIC中它们并不是。 (在ASCII / Unicode中是这样的)。你引用了一个以字母表开头的列表,但关键短语是“每个字符* 0之后*”,而该列表首先放置了字母表。 - Peter Cordes由于C标准保证字符0, 1, 2, 3, 4, 5, 6, 7, 8, 9始终按照它们的数字字符代码顺序排列。因此,如果您从另一个数字中减去'0'的字符代码,则会给出相对于0的位置,这就是它的值...
来自C标准,第5.2.1节字符集:
在源和执行基本字符集中,上述十进制数字列表中每个字符的值都应比前一个大1。
'0' '1' '2' '3' '4' '5' '6' '7' '8' '9',如ASCII表所示。'9'的ASCII码和'0'的ASCII码之间的差值,得到的结果将是9。0开始。如果您从0中减去一个较大的数字,则创建两个ASCII值之间的差异。所以,9的值为57,而0的值为48,因此如果您将57从48中减去,则得到9。请查看ASCII表。这里。首先,尝试:
cout << (int)'0' << endl;
现在尝试:
cout << (int)'9' << endl;
字符以文本形式表示数字,但作为数字时具有不同的值。 Windows使用数字来决定要打印哪个字符。因此,数字0x30代表Windows OS中的字符0。数字0x39代表字符9。毕竟,计算机只能识别数字,它不知道“char”是什么。
不幸的是,(int)('f' - '0')并不等于15。
这为您提供了各种字符及其表示它们的数字的Windows使用情况。 http://msdn.microsoft.com/en-us/library/windows/desktop/dd375731(v=vs.85).aspx
如果您需要在另一个操作系统中查找,请在Google中搜索:Virtual Key Codes <OSname>,以查看其他操作系统的代码。
 来源:
来源: