df1 <-
data.frame(c("male", "female", "male"),
c("1", "2", "3", "4", "5", "6"),
seq(141, 170))
names(df1) = c("gender", "age", "height")
df1$age <- factor(
df1$age,
levels = c(1, 2, 3, 4, 5, 6),
labels = c("16-24", "25-34", "35-44", "45-54", "55-64", "65+")
)
q1a = c(1, 0, 1, 0, 0, 1)
q1b = c(0, 0, 2, 2, 2, 0)
q1c = c(0, 0, 3, 3, 0, 3)
# 1,2 and 3 used to be compatible with existing datasets.
# Could change all to 1 if necessary.
df2 <- data.frame(q1a = q1a, q1b = q1b, q1c = q1c)
df1 <- cbind(df1, df2)
rm(q1a, q1b, q1c, df2)
我希望您能在R中复制SPSS中的多重响应问题的分析。
目前,我正在使用以下代码:
#creating function for analysing questions with grouped data
multfreqtable <- function(a, b, c) {
# number of respondents (for percent of cases)
totrep = sum(a == 1 | b == 2 | c == 3)
#creating frequency table
table_a = data.frame("a", sum(a == 1))
names(table_a) = c("question", "freq")
table_b = data.frame("b", sum(b == 2))
names(table_b) = c("question", "freq")
table_c = data.frame("c", sum(c == 3))
names(table_c) = c("question", "freq")
table_question <- rbind(table_a, table_b, table_c)
#remove individual question tables
rm(table_a, table_b, table_c)
#adding total
total = as.data.frame("Total")
totalsum = (sum(table_question$freq, na.rm = TRUE))
totalrow = cbind(total, totalsum)
names(totalrow) = c("question", "freq")
table_question = rbind(table_question, totalrow)
#adding percentage column to frequency table
percentcalc = as.numeric(table_question$freq)
percent = (percentcalc / totalsum) * 100
table_question <- cbind(table_question, percent)
#adding percent of cases column to frequency table
poccalc = as.numeric(table_question$freq)
percentofcases = (poccalc / totrep) * 100
table_question <- cbind(table_question, percentofcases)
#print percent of cases value
total_respondents <<- data.frame(totrep)
#remove all unnecessary data and values
rm(
total,
totalsum,
totalrow,
b,
c,
percent,
percentcalc,
percentofcases,
totrep,
poccalc
)
return(table_question)
}
#calling function - must tie to data.frame using $ !!!
q1_frequency <- multfreqtable(df1$q1a, df1$q1b, df1$q1c)
#renaming percent of cases - This is very important while using current method
total_respondents_q1 <- total_respondents
rm(total_respondents)
将其作为结果生成此表:
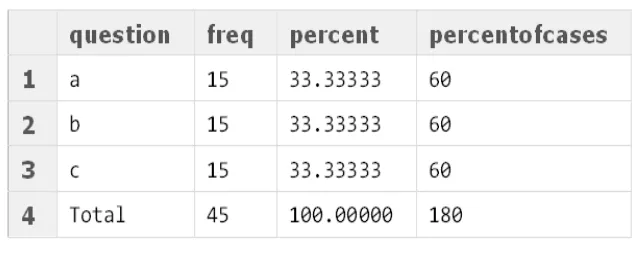
我正在寻找更有效的方法来完成这个任务,最好不需要编辑函数,即使有更多或更少的多项选择题也可以。