我们继承了一个运行在生产中并最近开始每10小时就崩溃的系统。基本上,如果系统无响应一分钟,我们的内部软件会标记该系统已经失败。我们发现我们的问题是Full GC循环持续1.5分钟,我们使用30 GB堆。现在的问题是,在短时间内我们不能进行很多优化,也不能快速地对服务进行分区,但我们需要尽快消除1.5分钟的停顿,因为这些停顿导致我们的系统在生产中崩溃。对于我们来说,可接受的延迟是20毫秒,但不再多。最快的调整系统的方法是什么?减少堆以频繁触发GC?使用System.gc()提示?还有其他解决方案吗?我们使用Java 8默认设置,并且我们有越来越多的用户 - 即越来越多的对象被创建。
一些GC统计: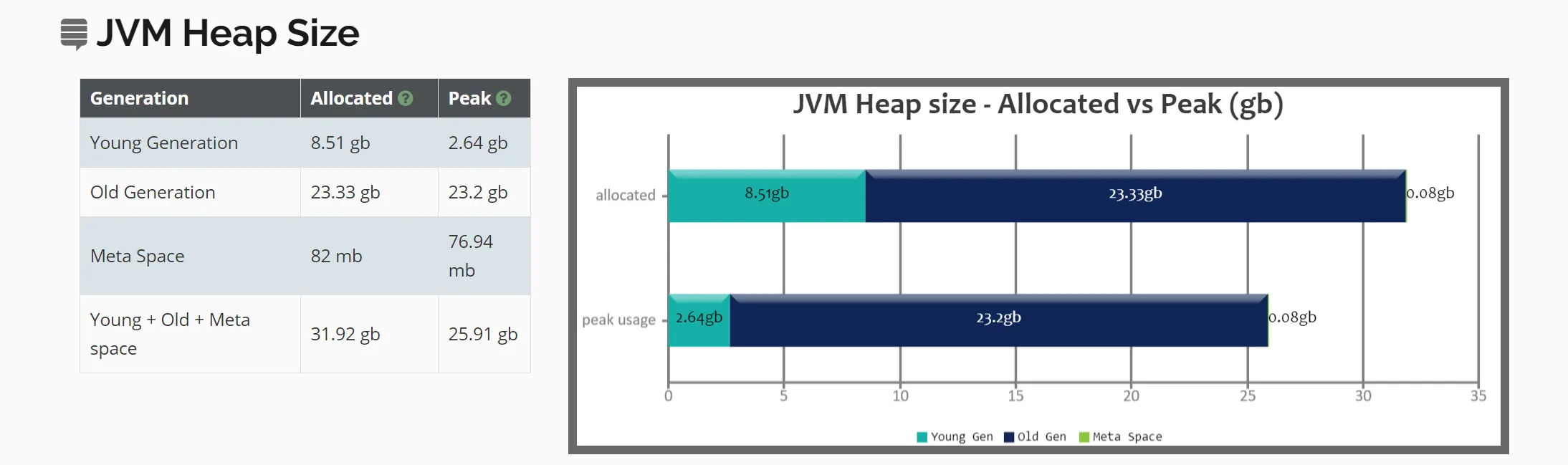
一些GC统计: