有没有好的方法在SQL Server中实现类似序列的东西?
有时候你不想使用GUID,除了它们很丑陋之外。也许你想要的序列并不是数字?此外,插入一行然后询问数据库数字似乎很hackish。
有没有好的方法在SQL Server中实现类似序列的东西?
有时候你不想使用GUID,除了它们很丑陋之外。也许你想要的序列并不是数字?此外,插入一行然后询问数据库数字似乎很hackish。
Sql Server 2012引入了SEQUENCE对象,允许您生成与任何表无关的连续数字值。
创建它们很容易:
CREATE SEQUENCE Schema.SequenceName
AS int
INCREMENT BY 1 ;
在插入之前使用它们的一个示例:
DECLARE @NextID int ;
SET @NextID = NEXT VALUE FOR Schema.SequenceName;
-- Some work happens
INSERT Schema.Orders (OrderID, Name, Qty)
VALUES (@NextID, 'Rim', 2) ;
查看我的博客,深入了解如何使用序列:
http://sqljunkieshare.com/2011/12/11/sequences-in-sql-server-2012-implementingmanaging-performance/
identity列的专用表来模拟sequence对象,就像我在我的回答中解释的那样。但是,在需要生成多个值的复杂情况下,这种方法会变得非常丑陋。 - Vladimir Baranov正如sqljunkieshare所说,从SQL Server 2012开始,有一个内置的SEQUENCE特性。
原始问题没有澄清,但我认为序列的要求是:
我想评论原始问题中的声明:
很抱歉,这里我们无法做太多事情。数据库是顺序编号的提供者,处理了所有你自己无法处理的并发问题。我看不到向数据库询问序列的下一个值之外的替代方案。必须有一个原子操作“给我序列的下一个值”,只有数据库可以提供这样的原子操作。没有客户端代码能够保证他是唯一使用该序列的人。"此外,插入一行然后询问数据库刚刚的数字似乎很不好。"
CREATE TABLE [dbo].[SequenceContractNumber]
(
[ContractNumber] [int] IDENTITY(1,1) NOT NULL,
CONSTRAINT [PK_SequenceContractNumber] PRIMARY KEY CLUSTERED ([ContractNumber] ASC)
)
CREATE PROCEDURE [dbo].[GetNewContractNumber]
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
SET XACT_ABORT ON;
DECLARE @Result int = 0;
IF @@TRANCOUNT > 0
BEGIN
-- Procedure is called when there is an active transaction.
-- Create a named savepoint
-- to be able to roll back only the work done in the procedure.
SAVE TRANSACTION ProcedureGetNewContractNumber;
END ELSE BEGIN
-- Procedure must start its own transaction.
BEGIN TRANSACTION ProcedureGetNewContractNumber;
END;
INSERT INTO dbo.SequenceContractNumber DEFAULT VALUES;
SET @Result = SCOPE_IDENTITY();
-- Rollback to a named savepoint or named transaction
ROLLBACK TRANSACTION ProcedureGetNewContractNumber;
RETURN @Result;
END
关于该过程的几点说明。
首先,如何在只有一个标识列的表中插入一行并不明显。答案是DEFAULT VALUES。
然后,如果在另一个事务内调用该存储过程,我希望它能正确工作。简单的ROLLBACK会回滚所有嵌套事务,而在我的情况下,我需要仅回滚对辅助表的INSERT,因此我使用了SAVE TRANSACTION。
没有savepoint_name或transaction_name的ROLLBACK TRANSACTION将回滚到事务的开头。当嵌套事务时,这个语句将回滚到最外层的BEGIN TRANSACTION语句的所有内部事务。
以下是我如何使用该存储过程(在其他大型存储过程内使用,例如创建新合同):
DECLARE @VarContractNumber int;
EXEC @VarContractNumber = dbo.GetNewContractNumber;
最近,我遇到了一个问题。我需要批量生成序列值,而不是逐个生成。
我需要一个过程,可以一次处理在给定季度内收到的所有付款。这种处理的结果可能是 ~20,000 个交易,我想将其记录在 Transactions 表中。我在这里有类似的设计。 Transactions 表具有内部的 IDENTITY 列,用户永远看不到它,并且它具有可在对账单上打印的人性化交易编号。因此,我需要一种方法来批量生成给定数量的唯一值。
本质上,我使用了相同的方法,但有一些特殊之处。
首先,没有直接的方法可以在只有一个 IDENTITY 列的表中插入多行。虽然有一种通过(滥用)MERGE 的解决方法,但最终我没有使用它。我决定添加一个虚拟的 Filler 列更容易。我的 Sequence 表始终为空,因此额外的列并不重要。
帮助表如下:
CREATE TABLE [dbo].[SequenceS2TransactionNumber]
(
[S2TransactionNumber] [int] IDENTITY(1,1) NOT NULL,
[Filler] [int] NULL,
CONSTRAINT [PK_SequenceS2TransactionNumber]
PRIMARY KEY CLUSTERED ([S2TransactionNumber] ASC)
)
-- Description: Returns a list of new unique S2 Transaction numbers of the given size
-- The caller should create a temp table #NewS2TransactionNumbers,
-- which would hold the result
CREATE PROCEDURE [dbo].[GetNewS2TransactionNumbers]
@ParamCount int -- not NULL
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
SET XACT_ABORT ON;
IF @@TRANCOUNT > 0
BEGIN
-- Procedure is called when there is an active transaction.
-- Create a named savepoint
-- to be able to roll back only the work done in the procedure.
SAVE TRANSACTION ProcedureGetNewS2TransactionNos;
END ELSE BEGIN
-- Procedure must start its own transaction.
BEGIN TRANSACTION ProcedureGetNewS2TransactionNos;
END;
DECLARE @VarNumberCount int;
SET @VarNumberCount =
(
SELECT TOP(1) dbo.Numbers.Number
FROM dbo.Numbers
ORDER BY dbo.Numbers.Number DESC
);
-- table variable is not affected by the ROLLBACK, so use it for temporary storage
DECLARE @TableTransactionNumbers table
(
ID int NOT NULL
);
IF @VarNumberCount >= @ParamCount
BEGIN
-- the Numbers table is large enough to provide the given number of rows
INSERT INTO dbo.SequenceS2TransactionNumber
(Filler)
OUTPUT inserted.S2TransactionNumber AS ID INTO @TableTransactionNumbers(ID)
-- save generated unique numbers into a table variable first
SELECT TOP(@ParamCount) dbo.Numbers.Number
FROM dbo.Numbers
OPTION (MAXDOP 1);
END ELSE BEGIN
-- the Numbers table is not large enough to provide the given number of rows
-- expand the Numbers table by cross joining it with itself
INSERT INTO dbo.SequenceS2TransactionNumber
(Filler)
OUTPUT inserted.S2TransactionNumber AS ID INTO @TableTransactionNumbers(ID)
-- save generated unique numbers into a table variable first
SELECT TOP(@ParamCount) n1.Number
FROM dbo.Numbers AS n1 CROSS JOIN dbo.Numbers AS n2
OPTION (MAXDOP 1);
END;
/*
-- this method can be used if the SequenceS2TransactionNumber
-- had only one identity column
MERGE INTO dbo.SequenceS2TransactionNumber
USING
(
SELECT *
FROM dbo.Numbers
WHERE dbo.Numbers.Number <= @ParamCount
) AS T
ON 1 = 0
WHEN NOT MATCHED THEN
INSERT DEFAULT VALUES
OUTPUT inserted.S2TransactionNumber
-- return generated unique numbers directly to the caller
;
*/
-- Rollback to a named savepoint or named transaction
ROLLBACK TRANSACTION ProcedureGetNewS2TransactionNos;
IF object_id('tempdb..#NewS2TransactionNumbers') IS NOT NULL
BEGIN
INSERT INTO #NewS2TransactionNumbers (ID)
SELECT TT.ID FROM @TableTransactionNumbers AS TT;
END
END
这是它的使用方法(在某个计算交易的大型存储过程中):
-- Generate a batch of new unique transaction numbers
-- and store them in #NewS2TransactionNumbers
DECLARE @VarTransactionCount int;
SET @VarTransactionCount = ...
CREATE TABLE #NewS2TransactionNumbers(ID int NOT NULL);
EXEC dbo.GetNewS2TransactionNumbers @ParamCount = @VarTransactionCount;
-- use the generated numbers...
SELECT ID FROM #NewS2TransactionNumbers AS TT;
SequenceS2TransactionNumber 表中。为此,我使用一个辅助的 Numbers 表。该表仅包含从1到100,000的整数数字,并在系统的其他地方使用。如果需要,我会通过自身的交叉连接将 Numbers 表扩展到100,000 * 100,000。#NewS2TransactionNumbers。我不能在 OUTPUT 子句中使用 #NewS2TransactionNumbers,因为 ROLLBACK 会清除它。幸运的是,表变量不会受到 ROLLBACK 的影响。@TableTransactionNumbers 作为 OUTPUT 子句的目标。然后我回滚事务以清理序列表。接着将生成的序列值从表变量 @TableTransactionNumbers 复制到临时表 #NewS2TransactionNumbers 中,因为只有临时表 #NewS2TransactionNumbers 可以被存储过程调用者看到。表变量 @TableTransactionNumbers 对于存储过程的调用者是不可见的。
此外,可以使用 OUTPUT 子句直接将生成的序列发送给调用者(如您在使用 MERGE 的注释变体中所见)。它本身很好用,但我需要在某个表中生成值,以便在调用存储过程时进行进一步处理。当我尝试这样做时:
INSERT INTO @TableTransactions (ID)
EXEC dbo.GetNewS2TransactionNumbers @ParamCount = @VarTransactionCount;
我遇到了一个错误
不能在INSERT-EXEC语句中使用ROLLBACK语句。
但是,我需要在EXEC内使用ROLLBACK,这就是为什么我最终需要有这么多临时表的原因。
经过这一切后,如果能切换到具有适当的SEQUENCE对象的最新版本的SQL服务器,那将是多么美好。
ASC 和 PK_SequenceContractNumber 在 CONSTRAINT [PK_SequenceContractNumber] PRIMARY KEY CLUSTERED ([ContractNumber] ASC) 中是什么意思? - Shaiju TSequenceContractNumber表具有聚集的主键。 PK_SequenceContractNumber是实施约束所创建的主键约束和相应索引的名称。在索引中,ASC表示按升序排序的ContractNumber。我在这里描述的方法的主要点是帮助表始终保持空白,具有IDENTITY列。插入一行,记录生成的ID并回滚事务。 - Vladimir Baranov标识列大致类似于序列。
BEGIN TRANSACTION
SELECT number from plain old table..
UPDATE plain old table, set the number to be the next number
INSERT your row
COMMIT
但是不要这样做。锁定会很糟糕...
我从SQL Server开始,对我来说,Oracle的“序列”方案看起来像是一个hack。我猜你从另一个方向来,对你而言,scope_identity()看起来像是一个hack。
放下吧。入乡随俗。
我曾经解决这个问题的方法是使用一个名为“Sequences”的表来存储所有我的序列以及一个名为“nextval”的存储过程。
SQL表:
CREATE TABLE Sequences (
name VARCHAR(30) NOT NULL,
value BIGINT DEFAULT 0 NOT NULL,
CONSTRAINT PK_Sequences PRIMARY KEY (name)
);
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'nextVal') AND type in (N'P', N'PC')) DROP PROCEDURE nextVal;
GO
CREATE PROCEDURE nextval
@name VARCHAR(30)
AS
BEGIN
DECLARE @value BIGINT
BEGIN TRANSACTION
UPDATE Sequences
SET @value=value=value + 1
WHERE name = @name;
-- SELECT @value=value FROM Sequences WHERE name=@name
COMMIT TRANSACTION
SELECT @value AS nextval
END;
插入一些序列:
INSERT INTO Sequences(name, value) VALUES ('SEQ_Workshop', 0);
INSERT INTO Sequences(name, value) VALUES ('SEQ_Participant', 0);
INSERT INTO Sequences(name, value) VALUES ('SEQ_Invoice', 0);
最终获取序列的下一个值,
execute nextval 'SEQ_Participant';
以下是一些用于从序列表中获取下一个值的C#代码:
public long getNextVal()
{
long nextval = -1;
SqlConnection connection = new SqlConnection("your connection string");
try
{
//Connect and execute the select sql command.
connection.Open();
SqlCommand command = new SqlCommand("nextval", connection);
command.CommandType = CommandType.StoredProcedure;
command.Parameters.Add("@name", SqlDbType.NVarChar).Value = "SEQ_Participant";
nextval = Int64.Parse(command.ExecuteScalar().ToString());
command.Dispose();
}
catch (Exception) { }
finally
{
connection.Dispose();
}
return nextval;
}
nextval 应该至少在表上设置一个独占锁。否则,两个并发调用将返回相同的数字。 - SQL PoliceCREATE SEQUENCE
在2005年和2008年,您可以使用公共表达式获取任意序列号的列表。
以下是一个示例(请注意MAXRECURSION选项很重要):
DECLARE @MinValue INT = 1;
DECLARE @MaxValue INT = 1000;
WITH IndexMaker (IndexNumber) AS
(
SELECT
@MinValue AS IndexNumber
UNION ALL SELECT
IndexNumber + 1
FROM
IndexMaker
WHERE IndexNumber < @MaxValue
)
SELECT
IndexNumber
FROM
IndexMaker
ORDER BY
IndexNumber
OPTION
(MAXRECURSION 0)
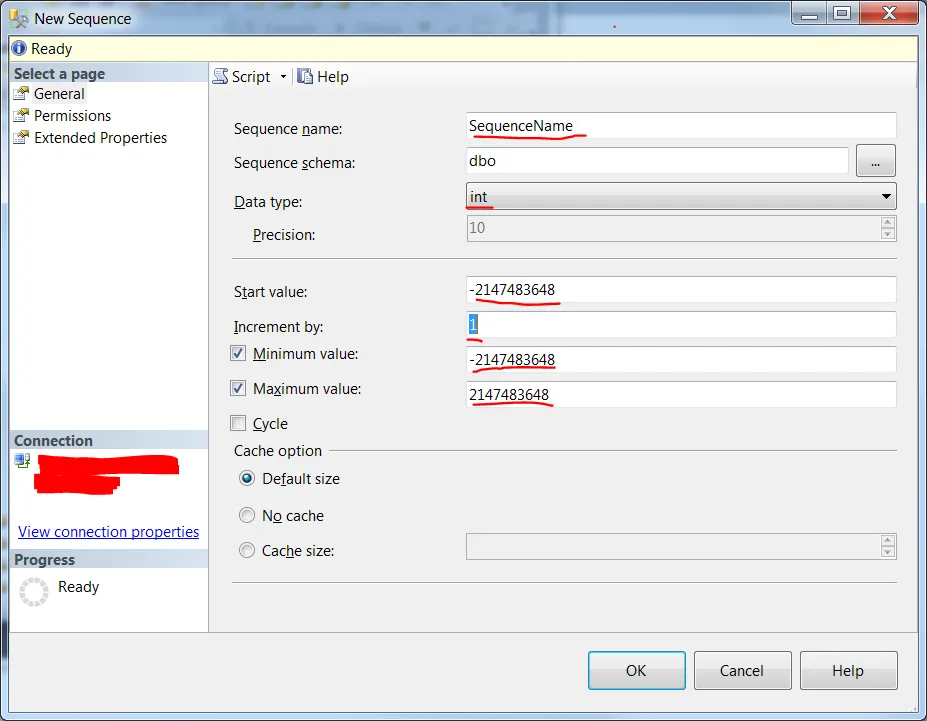
正如sqljunkiesshare所述,序列在SQL Server 2012中被添加。以下是使用GUI的方法。这相当于:
CREATE SEQUENCE Schema.SequenceName
AS int
INCREMENT BY 1 ;
注释:
默认的起始值、最小值和最大值是通过该数据类型的范围来确定的,在这种情况下,数据类型为int。如果您想使用其他数据类型,请在此处查看更多数据类型范围。
有很大的可能您希望您的序列从1开始,并且您的最小值也为1。
CREATE TABLE [SEQUENCE](
[NAME] [varchar](100) NOT NULL,
[NEXT_AVAILABLE_ID] [int] NOT NULL,
CONSTRAINT [PK_SEQUENCES] PRIMARY KEY CLUSTERED
(
[NAME] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE PROCEDURE CLAIM_IDS (@sequenceName varchar(100), @howMany int)
AS
BEGIN
DECLARE @result int
update SEQUENCE
set
@result = NEXT_AVAILABLE_ID,
NEXT_AVAILABLE_ID = NEXT_AVAILABLE_ID + @howMany
where Name = @sequenceName
Select @result as AVAILABLE_ID
END
GO