声明:这是从另一个关于Git的线程中转贴过来的,但我还是推荐Mercurial。它涉及企业上下文中的分布式版本控制系统,因此我希望跨越贴文可以接受。我稍微修改了一下,以更好地适应这个问题:
与普遍意见相反,我认为在企业环境中使用分布式版本控制系统是一个理想的选择,因为它可以实现非常灵活的工作流程。首先,我将谈论使用DVCS vs. CVCS的区别,然后介绍最佳实践,最后讨论关于Git。
企业环境下的DVCS vs. CVCS:
我不会在这里讨论一般的优缺点,而是关注您的具体情况。通常认为,在企业环境中使用DVCS需要比使用集中式系统更加有纪律的团队。这是因为集中式系统提供了一种简单的方法来“强制执行”您的工作流程,而使用分布式系统需要更多的沟通和纪律来坚持已经建立的惯例。虽然这可能看起来增加了额外的开销,但是我认为增加的沟通对于使其成为良好的过程是有益的。您的团队将需要就代码、变更以及项目状态进行沟通。
另一个纪律方面的维度是鼓励分支和实验。以下是Martin Fowlers最近在版本控制工具中发表的一句话,他为这种现象找到了一个非常简洁的描述。
DVCS鼓励快速分支进行试验。在Subversion中可以进行分支,但是它们对所有人都可见的事实会阻止人们开展试验性工作。同样,DVCS鼓励对工作进行检查点:将不完整的更改提交到本地存储库,这些更改甚至可能无法编译或通过测试。在Subversion的开发者分支上也可以这样做,但是这种分支在共享空间中使人们不太可能这样做。
DVCS通过有向无环图(DAG)中的全局唯一标识符提供变更集跟踪,而不是简单的文本差异,从而使其能够透明地跟踪变更集的起源和历史,这可能非常重要。
工作流程:
Larry Osterman(Windows团队的微软开发人员)在他的
博客文章中介绍了他们在Windows团队中采用的工作流程。其中最值得注意的是:
- 干净、高质量的代码仅存储在主干(主存储库)中
- 所有开发都在功能分支上进行
- 功能团队拥有团队存储库
- 定期将最新的主干更改合并到其功能分支中(前向集成)
- 完整的功能必须通过几个质量门(例如审核、测试覆盖率、Q&A)(各自的存储库)
- 如果功能完成且质量可接受,则将其合并到主干中(反向集成)
如您所见,让每个仓库独立存在可以使不同团队以不同的速度推进而解耦。另外,实现灵活的质量门控系统的可能性使得分布式版本控制系统(DVCS)与集中式版本控制系统(CVCS)有所区别。您也可以在这个层面上解决您的权限问题。只有少数人应该被允许访问主仓库。对于层次结构的每个级别,都要有一个单独的仓库和相应的访问策略。事实上,这种方法在团队层面上非常灵活。您应该让每个团队自行决定是否想要共享他们的团队仓库,还是希望采用更加等级化的方法,只有团队领导才能提交到团队仓库。
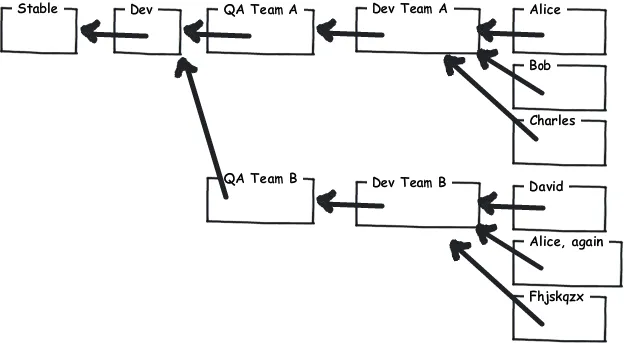
(这张图片是从Joel Spolsky的hginit.com中偷来的。)
在这一点上还有一件事情需要说,即使DVCS提供了很好的合并功能,这绝不是使用持续集成的替代品。即使在那个时候,你也有很大的灵活性:对于主干存储库,团队存储库,Q&A存储库等都可以使用CI。
企业环境中的Mercurial:
我不想在这里引发git vs. hg的争论,你已经考虑切换到DVCS了,这是正确的方向。以下是选择使用Mercurial而不是git的几个原因:
- 支持运行python的所有平台
- 在所有主要平台(win/linux/OS X)上有出色的GUI工具,第一流的合并/vdiff工具集成
- 非常一致的界面,对svn用户易于过渡
- 可以做到与git大部分相同的事情,但提供了更清晰的抽象。危险操作总是明确的。高级功能通过必须显式启用的扩展提供。
- 来自selenic的商业支持。
简而言之,在企业中使用DVCS时,我认为选择引入最少摩擦的工具非常重要。为了使过渡成功,特别需要考虑开发人员之间(关于VCS)的不同技能。
最后我想指出一些资源。Joel Spolsky 最近写了一篇论文,驳斥了很多反对 DVCS 的观点。必须提到其他人在很久以前就发现了这些反对观点。另一个好的资源是 Eric Sink 的博客,在那里他写了一篇关于企业 DVCS 面临的障碍的文章。