自版本12以来 - 在撰写本文时已经过去了2年+4个月(但在我看到的已接受答案的最后一次编辑之后),您可以使用
GENERATED FIELD轻松地进行一次性操作,而不必每次希望
SELECT一个新的po_number时都要计算它。
此外,您可以使用
TRANSLATE函数提取数字,这比@ErwinBrandstetter提出的
REGEXP_REPLACE解决方案更节省成本!
我会按照以下方式执行此操作(下面的所有代码都可以在fiddle
here上找到):
CREATE TABLE s
(
num TEXT,
new_num INTEGER GENERATED ALWAYS AS
(NULLIF(TRANSLATE(num, 'ABCDEFGHIJKLMNOPQRSTUVWXYZ. ', ''), '')::INTEGER) STORED
);
您好,这段文字的英译中翻译如下:
您可以根据需要在TRANSLATE函数中添加'ABCDEFG...'字符串 - 我在末尾加了小数点(.)和空格( )- 根据您的输入,您可能希望在那里添加更多字符!
并进行检查:
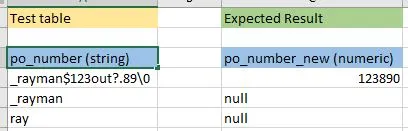
INSERT INTO s VALUES ('2'), (''), (NULL), (' ');
INSERT INTO t VALUES ('2'), (''), (NULL), (' ');
SELECT * FROM s;
SELECT * FROM t;
结果(两者相同):
num new_num
2 2
NULL
NULL
NULL
因此,我想检查我的解决方案有多有效率,所以我运行了以下测试,将10,000条记录插入到表
s 和
t 中,如下所示(来自
此处):
EXPLAIN (ANALYZE, BUFFERS, VERBOSE)
INSERT INTO t
with symbols(characters) as
(
VALUES ('ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789')
)
select string_agg(substr(characters, (random() * length(characters) + 1) :: INTEGER, 1), '')
from symbols
join generate_series(1,10) as word(chr_idx) on 1 = 1
join generate_series(1,10000) as words(idx) on 1 = 1
group by idx;
差异并不是很大,但是使用正则表达式的解决方案始终比使用INSERT语句更慢约25%,即使改变进行INSERT的表格顺序也是如此。
然而,当执行“原始”SELECT时,TRANSLATE解决方案真正发挥作用,如下所示:
EXPLAIN (ANALYZE, BUFFERS, VERBOSE)
SELECT
NULLIF(TRANSLATE(num, 'ABCDEFGHIJKLMNOPQRSTUVWXYZ. ', ''), '')::INTEGER
FROM s;
“
对于REGEXP_REPLACE解决方案也是一样。
差异非常明显,TRANSLATE函数的时间大约是另一个函数的25%。最后,为了公正起见,我也对这两个表格都进行了测试:
”
EXPLAIN (ANALYZE, BUFFERS, VERBOSE)
SELECT
num, new_num
FROM t;
"非常快速且完全相同!"