我写信是想知道有没有人知道如何加速Spark在EMR上的S3写入时间?
我的Spark作业需要超过4小时才能完成,但集群仅在前1.5小时内负载较高。
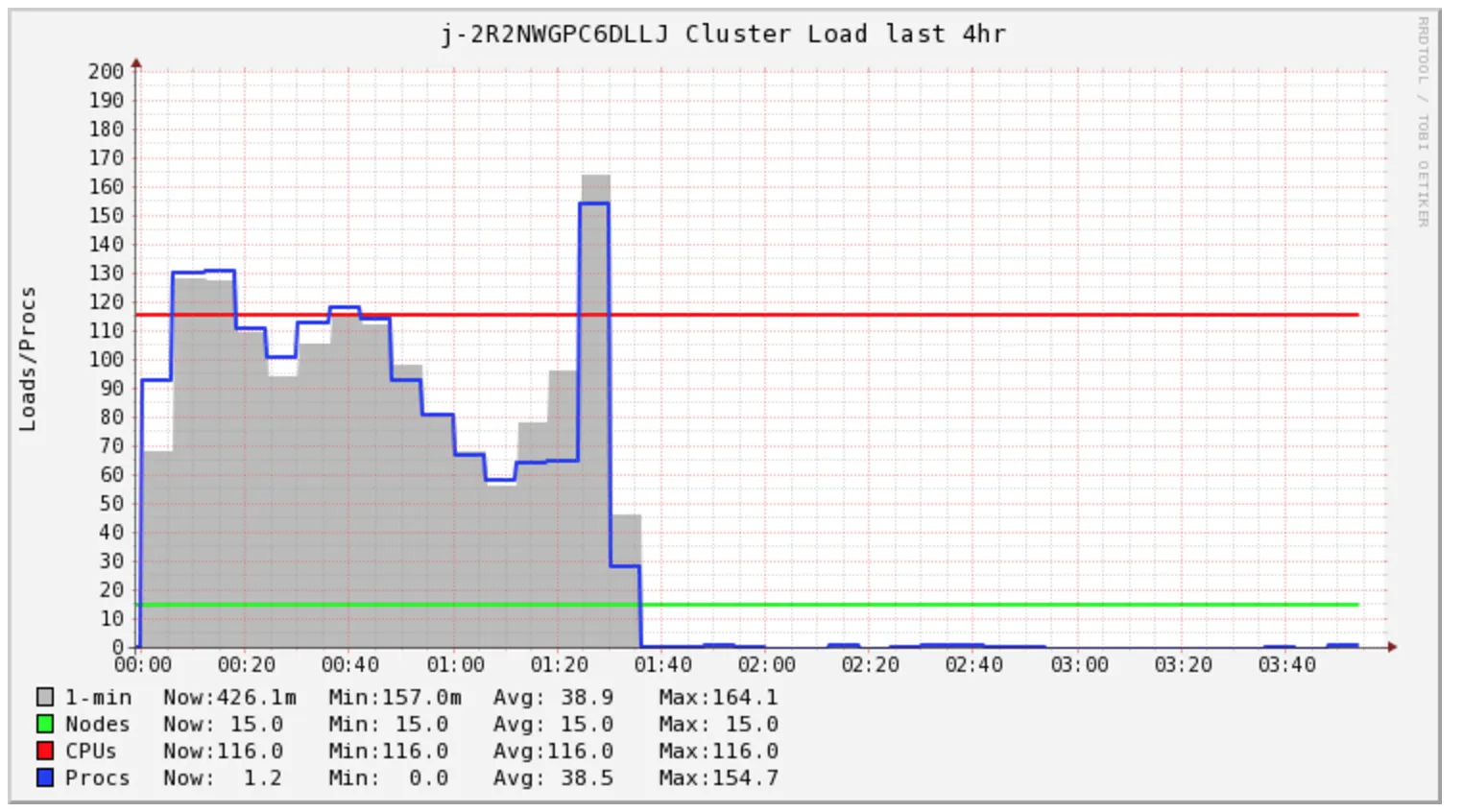
我很好奇Spark这段时间在做什么。我查看了日志,并发现有许多s3 mv命令,每个文件都有一个。直接在S3上查看后,我发现所有文件都在一个_temporary目录中。
此外,我担心我的集群成本,因为看起来我需要购买2小时的计算时间来完成此特定任务。然而,我最终购买了多达5小时的计算时间。我想知道在这种情况下EMR AutoScaling是否可以帮助降低成本。
一些文章讨论更改文件输出提交者算法,但我尝试过程中并没有取得太大成功。
sc.hadoopConfiguration.set("mapreduce.fileoutputcommitter.algorithm.version", "2")
将数据写入本地HDFS速度很快。我想知道发出一个hadoop命令将数据复制到S3是否更快?
s3-dist-cp将数据复制回S3。另外,如果您的EMR集群缺少s3-dist-cp命令,则必须在create-cluster命令中列出Hadoop。例如:--applications Name=Hadoop Name=Spark Name=Ganglia Name=zeppelin。 - jspooner