我很难完全理解正在发生的事情。
以下是我对底部代码的理解:
将A定义为指向指针地址的指针,该指针指向double类型的地址。
在堆上分配4个内存块,每个内存块都可以容纳一个指向double类型的地址。返回第一个分配给A的块的地址。
在堆上分配6个内存块,每个内存块都可以容纳double数据类型,并返回前面4个块中每个块的第一个地址。
假设A[0]更改了A所指向的地址上的值而不是A本身,则变量A仍包含四个指针中第一个块的地址。
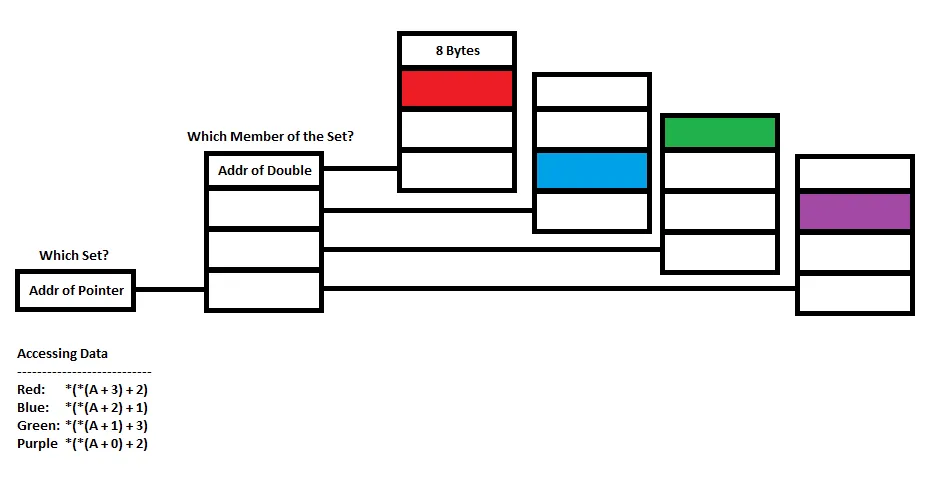
现在这就是链接在底部的图表发挥作用的地方。假设我想访问存储在红色块中的数据。我该如何做呢?
以下代码是否有效?
double data = *(*(A + 3) + 2);
我认为,A是一个指针,并且将其增加3应该会将地址增加与大小(double *)相同的字节数。对地址(A + 3)进行取消引用,我将得到第一个块的地址(假设它没有被重新分配)。通过增加所得到的地址2次并取消引用该地址,我应该得到红色块的值。
所以,如果我理解正确,在内存中存储了1 + M个指针。为什么?如果目标是存储MxN数据,为什么需要1 + M个指针?这些额外的指针似乎只有在想定义不同大小的行时才有帮助,但目标是定义矩形数组数据。
const int M = 4;
const int N = 6;
double **A;
A = malloc(M*sizeof(double *));
for (i = 0; i < N; i++) {
A[i]= malloc(N*sizeof(double));
}
图示:
附注: 我是一名电气工程学生,对C语言和正式的编程实践不太熟悉。我知道我对这么简单的代码比较苛刻,但我想确定我正确理解了指针和内存分配。它们一眼看上去就很难理解。这是我教授给我的一个矩阵乘法代码的一部分,我想把指针传递给一个函数,并让它访问和修改内存中的正确值。个人认为对于这段代码,我更喜欢看到二维数组,但我假设有一个很好的理由。
double A[M][N];来分配一个NM的矩阵,尽管对于大型矩阵,你不想将其分配在堆栈上。你可以使用VLA(可变长度数组)来分配内存,例如:double (*A)[N] = malloc(M * sizeof *A);。 - Kninnugint arr[10] = {...};然后你可以访问arr[0]、arr[1]直到arr[9]。这些语句等同于:*(&arr[0] + 0)、*(&arr[0] + 1)等(&arr[0]是第一个元素的地址,如果我写成*(arr + 1)它会超出数组的末尾,你也可以这样做:int * ptr = arr;然后使用*(ptr + 0)、*(ptr + 1),因为数组会退化为指针)。双指针看起来像链表,但与真正的链表不同,除了它所指向的地址之外,指针本身没有(其他)数据。 - Kninnug*(arr + 1)等同于*(&arr[0] + 1),因此不必取第一个元素的地址。我不知道为什么会有这种想法。 - Kninnug