我想生成0到1000之间不重复的独特随机数(即6不会出现两次),但是不想使用类似于O(N)搜索先前值的方法来实现。这是否可能?
22个回答
267
用0-1000的值初始化一个包含1001个整数的数组,并将变量max设置为数组当前最大索引(从1000开始)。选择一个介于0和max之间的随机数r,交换位置r处的数字和位置max处的数字,并返回现在位于位置max处的数字。将max减1并继续执行。当max为0时,将max重新设置为数组大小-1,并且无需重新初始化数组即可重新开始。
更新: 虽然我自己回答问题时想出了这种方法,但经过一些研究,我意识到这是Fisher-Yates的修改版本,称为Durstenfeld-Fisher-Yates或Knuth-Fisher-Yates。由于描述可能有点难以理解,因此我提供了以下示例(使用11个元素而不是1001个):
数组从11个元素初始化为array[n]=n开始,max起始为10:
+--+--+--+--+--+--+--+--+--+--+--+
| 0| 1| 2| 3| 4| 5| 6| 7| 8| 9|10|
+--+--+--+--+--+--+--+--+--+--+--+
^
max
在每次迭代中,会随机选择一个介于0和max之间的数字r,然后交换array[r]和array[max]的值,将新的array[max]返回,并将max减一:
max = 10, r = 3
+--------------------+
v v
+--+--+--+--+--+--+--+--+--+--+--+
| 0| 1| 2|10| 4| 5| 6| 7| 8| 9| 3|
+--+--+--+--+--+--+--+--+--+--+--+
max = 9, r = 7
+-----+
v v
+--+--+--+--+--+--+--+--+--+--+--+
| 0| 1| 2|10| 4| 5| 6| 9| 8| 7: 3|
+--+--+--+--+--+--+--+--+--+--+--+
max = 8, r = 1
+--------------------+
v v
+--+--+--+--+--+--+--+--+--+--+--+
| 0| 8| 2|10| 4| 5| 6| 9| 1: 7| 3|
+--+--+--+--+--+--+--+--+--+--+--+
max = 7, r = 5
+-----+
v v
+--+--+--+--+--+--+--+--+--+--+--+
| 0| 8| 2|10| 4| 9| 6| 5: 1| 7| 3|
+--+--+--+--+--+--+--+--+--+--+--+
...
经过11次迭代,数组中的所有数字都已被选择,最大值为0,并且数组元素已被洗牌:
+--+--+--+--+--+--+--+--+--+--+--+
| 4|10| 8| 6| 2| 0| 9| 5| 1| 7| 3|
+--+--+--+--+--+--+--+--+--+--+--+
此时,max可以重置为10并继续进行处理。
- Robert Gamble
22
6杰夫在他的洗牌帖子中暗示这种方法无法生成好的随机数。
http://www.codinghorror.com/blog/archives/001015.html - pro
16我认为不是;这对我来说看起来像Fisher-Yates算法,Jeff的帖子中也引用了它(作为好的例子)。 - Brent.Longborough
3@Robert: 我只是想指出,正如问题名称所示,“在O(1)时间内生成唯一的随机数”是不可能实现的。 - Charles
3@mikera:同意,但从技术上讲,如果你使用固定大小的整数,整个列表可以在O(1)(具有大常数2^32)中生成。此外,对于实际目的,"随机"的定义很重要--如果你真的想使用系统熵池,限制因素是生成随机位而不是计算本身,在这种情况下,n log n 再次成为相关的。但在你会使用(等效的)/dev/urandom 而不是 /dev/random 的情况下,“实际上”又回到了 O(n)。 - Charles
4我有点困惑,你需要每次执行N次迭代(例如此示例中为11次)才能获得所需的结果,这不意味着它是O(n)吗?因为你需要执行N次迭代才能从相同的初始状态获取N!个组合,否则你的输出只会是N种状态之一。 - Seph
显示剩余17条评论
73
你可以这样做:
- 创建一个0到1000的列表。
- 对列表进行洗牌。(参见Fisher-Yates shuffle以了解良好的方法。)
- 从洗牌后的列表中按顺序返回数字。
- Chris Jester-Young
8
5@Just Some Guy
N = 1000,所以你的意思是O(N/N),也就是O(1)。 - Guvante
1如果每次向洗牌数组中插入一个值都是一次操作,那么在插入1个值后,您可以获得1个随机值。2个值需要2个操作,以此类推,n个值需要n个操作。生成列表需要n个操作,因此整个算法的时间复杂度为O(n)。如果您需要1,000,000个随机值,则需要1,000,000个操作。 - Kibbee
3这样想,如果它是固定时间,那么对于10个随机数字和10亿个随机数字来说,所需的时间将是相同的。但由于洗牌需要O(n)时间,我们知道这不是真的。 - Kibbee
1多年来,我一直想修改@AdamRosenfield的编辑,将“amortized”改为“amortised”,但我无法让自己进行如此微小的编辑而没有其他更改,特别是因为该编辑已经存在5年了。不过,至少我应该在记录中说明这一点。 - C. K. Young
2现在,我有充分的理由去做这件事!http://meta.stackoverflow.com/q/252503/13 - C. K. Young
显示剩余3条评论
64
使用最大线性反馈移位寄存器。
它可以在几行C代码中实现,并且在运行时只做一些测试、分支、少量加法和位移。它不是真正的随机数,但它可以欺骗大多数人。
- plinth
7
12“这不是随机的,但它会欺骗大多数人。” 这适用于所有伪随机数生成器和此问题的所有可行答案。 但大多数人不会考虑到这一点。 因此,省略此注释可能会导致更多的赞... - f3lix
4"O(1)内存"是原因。 - Ash
3注意:它的内存复杂度为O(log N)。 - Paul Hankin
2使用这种方法,你如何生成0到800000之间的数字?有些人可能会使用周期为1048575(2^20-1)的LFSR,如果数字超出范围,则获取下一个数字,但这不是高效的方法。 - tigrou
1作为一个LFSR,它不能产生均匀分布的序列:整个将要生成的序列是由第一个元素定义的。 - ivan_pozdeev
显示剩余2条评论
32
您可以使用格式保留加密来加密计数器。您的计数器从0开始递增,加密使用您选择的密钥将其转换为任何基数和宽度的似乎随机值。例如,在本问题中:基数为10,宽度为3。
块密码通常具有固定的块大小,例如64或128位。但是,格式保留加密允许您采用标准密码(如AES)并制作一个更小的宽度密码,其基数和宽度可自行选择,算法仍然具有密码学上的强度。
它保证永远不会发生冲突(因为密码算法创建1:1映射)。它也是可逆的(双向映射),因此您可以取得结果数字并返回到起始的计数器值。
这种技术不需要存储洗牌数组等内存,这在内存有限的系统上可能是一个优点。
AES-FFX是实现这一目标的一种提议的标准方法。我已经尝试过一些基于AES-FFX思想的基本Python代码,尽管不完全符合规范——请在此处查看Python代码。它可以将计数器加密为一个看起来像随机的7位十进制数字或16位数字。这是基数为10,宽度为3(以给出0到999之间的数字)的示例:
000 733
001 374
002 882
003 684
004 593
005 578
006 233
007 811
008 072
009 337
010 119
011 103
012 797
013 257
014 932
015 433
... ...
要获得不同的非重复伪随机序列,请更改加密密钥。每个加密密钥都会产生一个不同的非重复伪随机序列。
- Craig McQueen
15
1这本质上是一个简单的映射,因此与LCG和LFSR没有任何区别,并且具有所有相关的缺陷(例如,在序列中相距超过“k”的值永远不会同时出现)。 - ivan_pozdeev
由于序列是恒定的且其中的每个数字都是唯一的,因此返回的组合完全由第一个数字定义。因此它不是完全随机的 - 只能生成可能组合的一小部分子集。 - ivan_pozdeev
3@ivan_pozdeev 不是必须实现特定的静态映射,也不是“组合结果完全由第一个数字定义”。由于配置参数比第一个数字的状态数(仅有一千个状态)要大得多,所以应该会有多个序列以相同的初始值开始,然后前往不同的后续值。任何现实的生成器都无法覆盖所有可能的排列空间;当 OP 没有要求时,将这种失败模式提出来并没有太大价值。 - sh1
5当正确实施时,使用一个由均匀随机选择的密钥的安全分组密码所生成的序列,将在计算上与真正的随机洗牌无法区别。也就是说,没有一种方法能够比测试所有可能的分组密码密钥并查看是否有任何一个密钥产生相同输出的方法更快速地区分此方法的输出和真正的随机洗牌。对于一个具有128位密钥空间的密码而言,这可能超出了目前人类可用的计算能力;对于256位密钥,则可能永远如此。 - Ilmari Karonen
@PabloH 从统计学上讲,它是一个均匀分布,就像高质量的加密算法一样。 - Craig McQueen
显示剩余10条评论
23
您可以使用一个线性同余生成器。其中
m(模数)将是大于1000的最近素数。当您获得超出范围的数字时,只需获取下一个数字即可。该序列仅在所有元素出现一次后才会重复,并且无需使用表格。请注意此生成器的缺点(包括缺乏随机性)。- Paul de Vrieze
3
11009是1000之后的第一个质数。 - Teepeemm
一个线性同余生成器(LCG)在连续数字之间具有高相关性,因此在大量情况下,_组合_不会非常随机(例如,在序列中相距超过
k的数字永远不会同时出现)。 - ivan_pozdeevm 应该是元素数量 1001(1000 + 1 代表零),您可以使用 Next = (1002 * Current + 757) mod 1001; - Max Abramovich
9
我认为 线性同余发生器 将是最简单的解决方案。
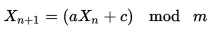
只有a、c和m这三个值存在三个限制条件:
- m和c互质;
- a-1可被m的所有质因数整除;
- 如果m是4的倍数,则a-1可被4整除。
PS:该方法已经被提到,但帖子中对常量值作出了错误假设。以下常量值应适用于您的情况:
在您的情况下,您可以使用a = 1002、c = 757、m = 1001。
X = (1002 * X + 757) mod 1001
- Max Abramovich
8
对于像0...1000这样的小数字,创建包含所有数字并将其打乱的列表很简单。但是如果要抽取的数字集非常大,则有另一种优雅的方法:使用密钥和加密哈希函数构建伪随机排列。请参见以下类似于C ++的示例伪代码:
unsigned randperm(string key, unsigned bits, unsigned index) {
unsigned half1 = bits / 2;
unsigned half2 = (bits+1) / 2;
unsigned mask1 = (1 << half1) - 1;
unsigned mask2 = (1 << half2) - 1;
for (int round=0; round<5; ++round) {
unsigned temp = (index >> half1);
temp = (temp << 4) + round;
index ^= hash( key + "/" + int2str(temp) ) & mask1;
index = ((index & mask2) << half1) | ((index >> half2) & mask1);
}
return index;
}
在这里,
hash只是一种将字符字符串映射到可能很大的无符号整数的任意伪随机函数。函数randperm是0...pow(2,bits)-1内所有数字的排列,假设有一个固定的密钥。这是由于构造过程中改变变量index的每个步骤都是可逆的。这受到费斯特密码的启发。- sellibitze
3
与https://dev59.com/3nVC5IYBdhLWcg3wvT7g#16097246相同,对于序列的随机性检测同样失败。 - ivan_pozdeev
2@ivan_pozdeev:理论上,假设计算能力无限,是的。然而,假设上面代码中使用的
hash()是一个安全的伪随机函数,这个构造将可证明地(Luby&Rackoff,1988)产生一个伪随机置换,它不能被区分为真正的随机洗牌,使用比完整密钥空间的穷举搜索少得多的努力,这是指数级的密钥长度。即使对于相当大的密钥(例如128位),这也超出了地球上可用的总计算能力。 - Ilmari Karonen顺便说一下,为了使这个论点更加严谨,我更喜欢用HMAC替换上面的临时
hash(key + "/" + int2str(temp))构造,其安全性可以被证明降低到底层哈希压缩函数的安全性。此外,使用HMAC可能会使某些人不太可能错误地尝试使用不安全的非加密哈希函数来构建这个结构。 - Ilmari Karonen5
您可以使用我在这里描述的Xincrol算法:
http://openpatent.blogspot.co.il/2013/04/xincrol-unique-and-random-number.html
这是一种纯算法方法,可以生成随机但唯一的数字,而不需要使用数组、列表、排列或重负载的CPU。
最新版本还允许设置数字范围。例如,如果我想要0-1073741821范围内的唯一随机数。
我实际上已经将它用于:
- 播放每首歌曲随机的MP3播放器,但每个专辑/目录只播放一次
- 基于像素的视频帧溶解效果(快速平滑)
- 为签名和标记创建秘密“噪音”雾化图像(隐写术)
- 用于通过数据库对大量Java对象进行序列化的数据对象ID
- 三重多数存储位保护
- 地址+值加密(每个字节不仅加密还会移动到缓冲区中的新加密位置)。这确实使密码分析家对我很生气 :-)
- 短信、电子邮件等的纯文本到类似加密文本的加密
- 我的德州扑克计算器(THC)
- 几个用于模拟、洗牌、排名等的游戏
- 更多
它是开放的,免费的。试试看吧...
- Tod Samay
2
那个方法对于十进制值是否可行,例如将一个三位数的十进制计数器混淆以始终产生三位数的十进制结果? - Craig McQueen
5
无需数组即可解决此问题。需要一个位掩码和一个计数器。将计数器初始化为零并在接续的调用上递增。使用位掩码(在启动时随机选择或固定)与计数器异或以生成伪随机数。如果不能超过1000,请勿使用宽度大于9位的位掩码。(换句话说,位掩码是不超过511的整数)。确保当计数器超过1000时,将其重置为零。此时,您可以选择另一个随机位掩码 - 如果您喜欢 - 以以不同的顺序生成相同的数字集合。
- Max
3
2那比一个LFSR骗不了更少的人。 - starblue
512 到 1023 范围内的位掩码也可以。如果想要更多的虚假随机性,请参考我的答案。 :-) - sellibitze
本质上等同于 https://dev59.com/3nVC5IYBdhLWcg3wvT7g#16097246,还会对序列的随机性造成影响。 - ivan_pozdeev
3
这个问题 如何高效地生成一个在0到上限N之间的K个不重复整数列表 已经被链接为重复 - 如果你想要一些每个生成随机数都是O(1)(没有O(n)启动成本)的东西,那么有一个简单的方法可以使接受的答案更好。
创建一个空的无序映射(一个空的有序映射将需要每个元素O(log k))从整数到整数 - 而不是使用初始化的数组。 如果最大值是1000,则将其设置为1000,
创建一个空的无序映射(一个空的有序映射将需要每个元素O(log k))从整数到整数 - 而不是使用初始化的数组。 如果最大值是1000,则将其设置为1000,
- 选择一个介于0和最大值之间的随机数r。
- 确保无序映射中存在r和max两个元素。如果它们不存在,则创建它们并将它们的值设置为它们的索引。
- 交换元素r和max
- 返回元素max并将max减1(如果max变为负数,则完成)。
- 回到步骤1。
- Hans Olsson
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
O(n)),那么下面许多答案都是错误的,包括被接受的答案。 - jww