我正在处理一个sql server 2008数据库和asp.net mvc网络电商应用程序。
我有不同的用户向数据库提供其产品,并希望比较具有相似名称的产品的价格。 我知道字符串匹配是与领域相关的,但我仍然需要最好的通用解决方案。
什么是最有效的方式来分组搜索结果? 我应该递归地使用Levenshtien Distance算法比较每个记录吗? 我是在DB中还是在代码中执行它? 有没有一种方法可以实时实现SSIS模糊分组来完成此任务? 是否可以使用Sql server 2008全文搜索以高效的方式进行?
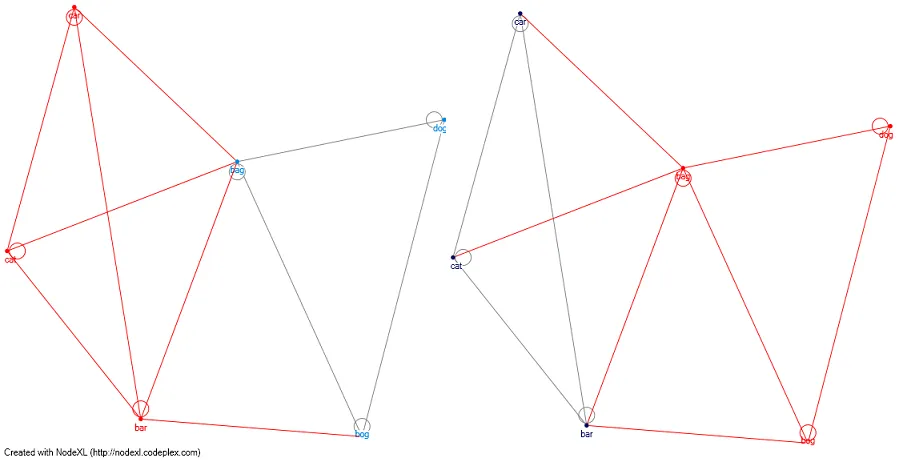
编辑1: 那么网络图分析呢?如果我使用Levenshtien Distance算法定义矩阵,我可以使用聚类算法(例如:clauset newman moore)并分离彼此没有语音路径的组。 我已经为Nick Johnson(请参见评论)附上了猫狗示例(红线是聚类),通过使用clauset newman moore,我创建了2个不同的聚类并将猫与狗分开。
你觉得呢?