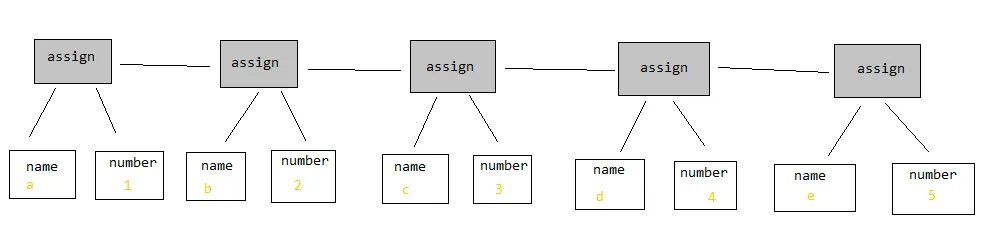
在第一个例子中,沿着主节点向“右”移动将使您通过程序前进,但在第二个例子中,仅需按照每个节点上的下一个指针进行操作即可完成相同的操作。似乎第二种方法更正确,因为您不需要像第一个节点那样拥有潜在的极长指针数组的特殊节点类型。
我几乎总是更喜欢第一种方法,并且当您不需要维护对下一个节点的指针时,构建AST会更容易。
我认为通常最好让所有对象都从一个共同的基类派生,就像这样:
abstract class Expr { }
class Block : Expr
{
Expr[] Statements { get; set; }
public Block(Expr[] statements) { ... }
}
class Assign : Expr
{
Var Variable { get; set; }
Expr Expression { get; set; }
public Assign(Var variable, Expr expression) { ... }
}
class Var : Expr
{
string Name { get; set; }
public Variable(string name) { ... }
}
class Int : Expr
{
int Value { get; set; }
public Int(int value) { ... }
}
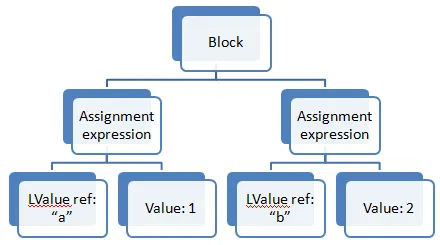
生成的AST如下:
Expr program =
new Block(new Expr[]
{
new Assign(new Var("a"), new Int(1)),
new Assign(new Var("b"), new Int(2)),
new Assign(new Var("c"), new Int(3)),
new Assign(new Var("d"), new Int(4)),
new Assign(new Var("e"), new Int(5)),
});
 或者如下:
或者如下:
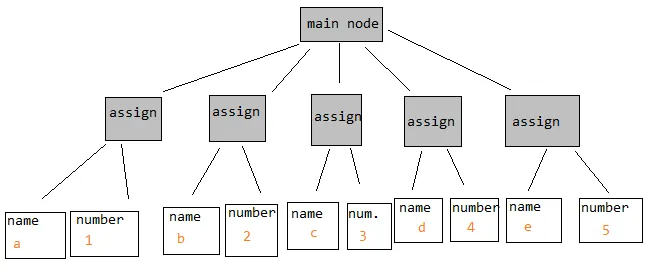
 这是你的第一个例子,缩短并更恰当地将“主”节点(一个概念性的替代品)命名为“块”,以反映在命令式编程语言中包含一系列语句的常见构造。不同类型的节点具有不同类型的子节点,有时这些子节点包括重要的子节点集合,如“block”的情况。同样的问题可能出现在,比如数组初始化中:
这是你的第一个例子,缩短并更恰当地将“主”节点(一个概念性的替代品)命名为“块”,以反映在命令式编程语言中包含一系列语句的常见构造。不同类型的节点具有不同类型的子节点,有时这些子节点包括重要的子节点集合,如“block”的情况。同样的问题可能出现在,比如数组初始化中: