我正在 Codeforces 上解决一些问题。通常我首先检查字符是否为大写或小写英文字符,然后减去或加上32以将其转换为相应的字符。但我发现有人使用 ^= 32 来完成同样的事情。这是代码:
char foo = 'a';
foo ^= 32;
char bar = 'A';
bar ^= 32;
cout << foo << ' ' << bar << '\n'; // foo is A, and bar is a
我已经搜索了这个问题的解释,但没有找到。那么为什么它有效呢?
我正在 Codeforces 上解决一些问题。通常我首先检查字符是否为大写或小写英文字符,然后减去或加上32以将其转换为相应的字符。但我发现有人使用 ^= 32 来完成同样的事情。这是代码:
char foo = 'a';
foo ^= 32;
char bar = 'A';
bar ^= 32;
cout << foo << ' ' << bar << '\n'; // foo is A, and bar is a
我已经搜索了这个问题的解释,但没有找到。那么为什么它有效呢?
让我们来看一下ASCII码表的二进制表示。
A 1000001 a 1100001
B 1000010 b 1100010
C 1000011 c 1100011
...
Z 1011010 z 1111010
32 的二进制表示是 0100000 ,这是区分大小写字母的唯一差别。因此,切换该位可以切换字母的大小写。
foobar []和foobar{}是相同的昵称,因为昵称是不区分大小写的,而IRC起源于斯堪的纳维亚 :) - ZeroKnight这是因为ASCII值是由非常聪明的人选择的事实。
foo ^= 32;
这个翻转1 foo 的第六低位(ASCII排序的大写标志),将 ASCII 大写字母转换为小写,反之亦然。
+---+------------+------------+
| | Upper case | Lower case | 32 is 00100000
+---+------------+------------+
| A | 01000001 | 01100001 |
| B | 01000010 | 01100010 |
| ... |
| Z | 01011010 | 01111010 |
+---+------------+------------+
'A' ^ 32
01000001 'A'
XOR 00100000 32
------------
01100001 'a'
通过异或的属性,'a' ^ 32 == 'A'。
C++不要求使用ASCII表示字符。另一种变体是EBCDIC。此技巧仅适用于ASCII平台。更具可移植性的解决方案是使用std::tolower和std::toupper,提供的奖励是区域设置感知(它并不能自动解决所有问题,参见评论):
bool case_incensitive_equal(char lhs, char rhs)
{
return std::tolower(lhs, std::locale{}) == std::tolower(rhs, std::locale{}); // std::locale{} optional, enable locale-awarness
}
assert(case_incensitive_equal('A', 'a'));
1) 由于32等于1 << 5(2的5次方),因此它会翻转第6位(从1开始计数)。
请允许我说,虽然看起来很聪明,但这真的是一个非常愚蠢的技巧。如果有人在2019年向您推荐此技巧,请打他。尽你所能狠狠地打他。
当然,如果您知道自己永远不会使用除英语以外的任何语言,那么您可以在自己的软件中使用此技巧,而其他人则不能。
30-35年前,计算机只能够处理ASCII编码下的英文和可能两种主要欧洲语言,因此该技巧曾经是可以接受的。但是......现在不再是这样了。
该技巧之所以有效,是因为美式拉丁大写字母和小写字母相距恰好0x20,并以相同的顺序出现,这只相差一位的二进制位被切换。
现在,为欧洲西部创建代码页(后来是Unicode联盟)的人足够聪明,如对于德语Umlauts和法语重音元音字母,他们保持了此方案。但是对于ß,他们没有这样做(直到有人在2017年说服Unicode联盟,并有一份大型虚假新闻印刷杂志报道此事,实际上说服了Duden——对此不发表评论),因为ß没有大写字母(转换为SS)。现在ß有了大写字母,但这两个字符相距0x1DBF而不是0x20。
它可以工作是因为,在ASCII和派生编码中,“a”和“A”的差异是32,而32也是第六位的值。通过使用异或翻转第6个位,从而在大写字母和小写字母之间进行转换。
你的字符集实现很可能是ASCII。如果我们看一下下表:
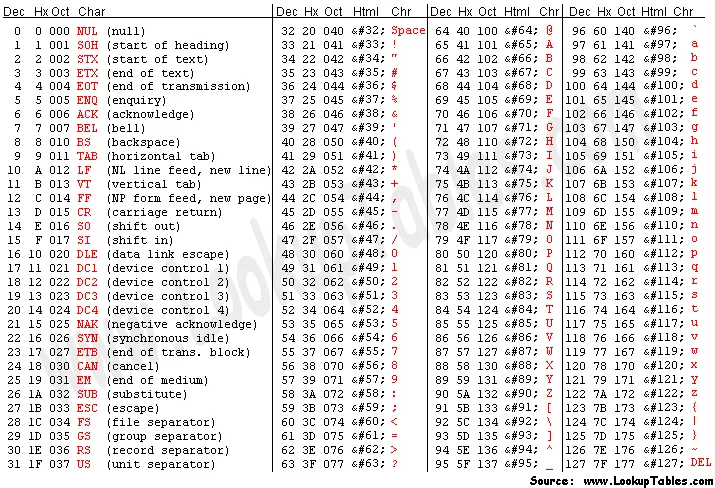
我们可以看到,小写字母和大写字母之间的值恰好相差32。因此,如果我们执行^= 32(即切换第六位最低有效位),它就会在小写字母和大写字母之间切换。
请注意,它适用于所有符号,而不仅仅是字母。它会将一个具有不同第六位的相应字符进行切换,从而得到一对反复切换的字符。对于字母,相应的大/小写字符形成这样一对。 NUL 将变为 Space,反之亦然,而 @ 与反引号切换。基本上,此图表上第一列中的任何字符都会与其右侧的字符切换,第三列和第四列也是如此。
虽然它可以在某些系统上正常工作,但我不建议使用这个hack。相反,请使用toupper和tolower以及isupper等查询函数。
32 ^ 32 是0,而不是64。 - NathanOliver[a-z]和[A-Z]才是“字母”。其余的都是遵循相同规则的巧合。如果有人要求你将“]”变成大写字母,它仍然会是“]”-“}”不是“]”的“大写字母”。 - freedomn-m这就是 ASCII 的工作原理。
然而,利用它时,您会失去 可移植性,因为 C++ 不会坚持使用 ASCII 编码。
这就是为什么在 C++ 标准库中实现了函数 std::toupper 和 std::tolower - 您应该使用这些函数。
ASCII被设计为使得shift和ctrl键可以实现而无需太多(或者也许没有ctrl需要任何)逻辑 - 可能只需要一些门。将电线协议存储为任何其他字符编码可能更有意义(不需要进行软件转换)。键盘上的Control修饰键基本上会清除您键入字符的前三位,只留下底部的五位并将其映射到0..31范围。因此,例如,Ctrl-SPACE、Ctrl-@和Ctrl-'都意味着NUL。
非常旧的键盘使用切换32或16位来完成Shift操作;这就是为什么ASCII中小写字母和大写字母之间的关系如此规律,数字和符号以及某些符号对之间的关系也有点规律。甚至可以通过移位16位来生成一些ASR-33不具备的标点符号; 因此,例如,Shift-K(0x4B)变成了 [(0x5B)。
这篇链接文章还解释了许多奇怪的黑客惯例,比如And control H does a single character and is an old^H^H^H^H^H classic joke.(在这里发现)。
foo ^= (foo & 0x60) == 0x20 ? 0x10 : 0x20来实现ASCII字符的移位切换,但由于其他答案中所述的原因,这仅适用于ASCII字符,因此不明智。它可能也可以通过无分支编程来改进。 - Iiridaynfoo ^= 0x20 >> !(foo & 0x40)会更简单。同时也是为什么简洁的代码通常被认为难以阅读的好例子 ^_^。 - Iiridayn使用32(二进制中的00100000)进行异或操作将设置或重置第六位(从右边开始计数)。这等价于加上或减去32。
相关的ASCII技巧:通过强制小写字母c |= 0x20,然后检查是否(无符号)c - 'a' <= ('z'-'a'),可以检查字母ASCII字符。因此,只需3个操作:OR + SUB + CMP与常数25进行比较。当然,编译器知道如何优化(c>='a' && c<='z') 就像这样为您转换成汇编语言,所以最多应该自己做c|=0x20部分。自己完成所有必要的类型转换非常不方便,特别是为了解决默认整数提升为有符号int的问题。
unsigned char lcase = y|0x20;
if (lcase - 'a' <= (unsigned)('z'-'a')) { // lcase-'a' will wrap for characters below 'a'
// c is alphabetic ASCII
}
// else it's not
换句话说:
unsigned char lcase = y|0x20;
unsigned char alphabet_idx = lcase - 'a'; // 0-index position in the alphabet
bool alpha = alphabet_idx <= (unsigned)('z'-'a');
另请参阅如何将C++字符串转换为大写(仅针对ASCII字符的SIMD字符串toupper,使用该检查掩码操作数进行XOR。)
还有如何访问字符数组并将小写字母变为大写字母,反之亦然 (使用SIMD内在函数的C语言和标量x86汇编大小写翻转,仅修改字母ASCII字符,不修改其他字符。)
char的高位设置。 (因此,没有任何字节是单个字符的多字节UTF-8编码的一部分,可能具有不同的大/小写反转)。如果发现任何问题,则可以在该16字节块或整个字符串的其余部分上退回到标量。
甚至有一些语言环境,其中对ASCII范围内某些字符执行toupper()或tolower()会产生超出该范围的字符,特别是土耳其语,其中I ↔ ı和İ ↔ i。在这些区域设置中,您需要进行更复杂的检查,或者根本不尝试使用此优化。
但在某些情况下,您可以假设ASCII而不是UTF-8,例如使用LANG=C(POSIX语言环境)的Unix实用程序,而不是en_CA.UTF-8或其他。
但如果您可以验证它是安全的,您可以比在循环中调用toupper()(如5倍)更快地将中等长度的字符串转换为大写,并且最后我测试了Boost 1.58,比执行每个字符的愚蠢的dynamic_cast的boost::to_upper_copy<char*, std::string>()要快得多。
toupper和tolower函数来切换字符大小写。 - NathanOliver