我在使用Python 3.5.2、python-pdfkit以及wkhtmltox-0.12.2时,遇到了一个难题,即无法生成带有非ASCII字符的简单PDF文件。以下是我能够编写的最简单的示例:
这就像输出文档的样子: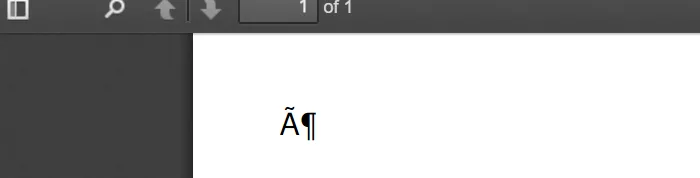
import pdfkit
html_content = u'<p>ö</p>'
pdfkit.from_string(html_content, 'out.pdf')
这就像输出文档的样子:
pdfkit.from_file()使其运作? - GitHunter0