假设我有以下两张图片A和B。
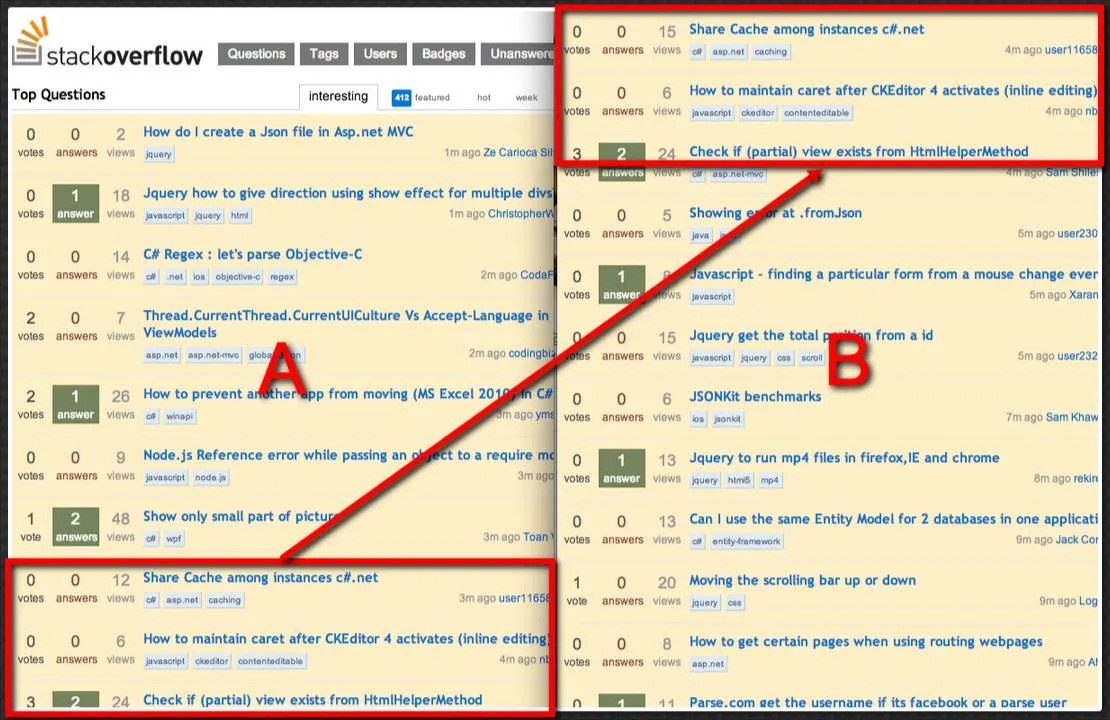
注意,A的底部与B的顶部重叠了n行像素,用两个红色矩形表示。 A和B具有相同的列数,但可能具有不同的行数。
两个问题:
- 给定A和B,如何高效地确定
n? - 如果以某种方式更改B,使其30%-50%的像素完全被替换(例如,想象左上角显示的投票/答案/查看次数被广告横幅替换),如何确定
n?
如果有人能指出任何语言(首选C / C ++,C#,Java和JavaScript)中的算法或更好的实现,将不胜感激。
假设我有以下两张图片A和B。
注意,A的底部与B的顶部重叠了n行像素,用两个红色矩形表示。 A和B具有相同的列数,但可能具有不同的行数。
两个问题:
n?n?如果有人能指出任何语言(首选C / C ++,C#,Java和JavaScript)中的算法或更好的实现,将不胜感激。
#!/bin/bash
# Grab page 2 as "A" and page 3 as "B"
# webkit2png -F -o A http://stackoverflow.com/questions?page=2&sort=newest
# webkit2png -F -o B http://stackoverflow.com/questions?page=3&sort=newest
BLOBH=256 # blob height
BLOBW=256 # blob width
# Get height of x.png
XHEIGHT=$(identify -format "%h" x.png)
# Crop a column 256 pixels out of a.png that doesn't contain adverts or junk, into x.png
convert a.png -crop ${BLOBW}x+0+0 x.png
# Crop a rectangle 256x256 pixels out of top left corner of b.png, into y.png
convert b.png -crop ${BLOBW}x${BLOBH}+0+0 y.png
# Now slide y.png up across x.png, starting at the bottom of x.png
# ... differencing the two images as we go
# ... stop when the difference is nothing, i.e. they are the same and difference is black image
lines=0
while :; do
OFFSET=$((XHEIGHT-BLOBH-1-lines))
if [ $OFFSET -lt 0 ]; then exit; fi
FN=$(printf "out-%04d.png" $lines)
diff=$(convert x.png -crop ${BLOBW}x${BLOBH}+0+${OFFSET} +repage \
y.png \
-fuzz 5% -compose difference -composite +write $FN \
\( +clone -evaluate set 0 \) -metric AE -compare -format "%[distortion]" info:)
echo $diff:$lines
((lines++))
done
n=$((BLOBH+lines))
class Image
{
public:
virtual ~Image() {}
typedef int Pixel;
virtual Pixel* getRow(int rowId) const = 0;
virtual int getWidth() const = 0;
virtual int getHeight() const = 0;
};
class Analyser
{
Analyser(const Image& a, const Image& b)
: a_(a), b_(b) {}
typedef Image::Pixel* Section;
static const int numStrips = 16;
struct StripId
{
StripId(int r = 0, int c = 0)
: row_(r), strip_(c)
{}
int row_;
int strip_;
};
typedef std::unordered_map<unsigned, StripId> StripTable;
int numberOfOverlappingRows()
{
int commonWidth = std::min(a_.getWidth(), b_.getWidth());
int stripWidth = commonWidth/numStrips;
StripTable aHash;
createStripTable(aHash, a_, stripWidth);
StripTable bHash;
createStripTable(bHash, b_, stripWidth);
// This is the position that the bottom row of A appears in B.
int bottomOfA = 0;
bool canFindBottomOfAInB = canFindLine(a_.getRow(a_.getHeight() - 1), bHash, stripWidth, bottomOfA);
int topOfB= 0;
bool canFindTopOfBInA = canFindLine(b_.getRow(0), aHash, stripWidth, topOfB);
int topOFBfromBottomOfA = a_.getHeight() - topOfB;
// Expect topOFBfromBottomOfA == bottomOfA
return bottomOfA;
}
bool canFindLine(Image::Pixel* source, StripTable& target, int stripWidth, int& matchingRow)
{
Image::Pixel* strip = source;
std::map<int, int> matchedRows;
for(int index = 0; index < stripWidth; ++index)
{
Image::Pixel hashValue = getHashOfStrip(strip,stripWidth);
bool match = target.count(hashValue) > 0;
if (match)
{
++matchedRows[target[hashValue].row_];
}
strip += stripWidth;
}
// Can set a threshold requiring more matches than 0
if (matchedRows.size() == 0)
return false;
// FIXME return the most matched row.
matchingRow = matchedRows.begin()->first;
return true;
}
Image::Pixel* getStrip(const Image& im, int row, int stripId, int stripWidth)
{
return im.getRow(row) + stripId * stripWidth;
}
static Image::Pixel getHashOfStrip(Image::Pixel* strip, unsigned width)
{
Image::Pixel hashValue = 0;
for(unsigned col = 0; col < width; ++col)
{
hashValue |= *(strip + col);
}
}
void createStripTable(StripTable& hash, const Image& image, int stripWidth)
{
for(int row = 0; row < image.getHeight(); ++row)
{
for(int index = 0; index < stripWidth; ++index)
{
// Warning: Not this simple!
// If images are sourced from lossy intermediate and hence pixels not _exactly_ the same, need some kind of fuzzy equality here.
// Details are going to depend on the image format etc, but this is the gist.
Image::Pixel* strip = getStrip(image, row, index, stripWidth);
Image::Pixel hashValue = getHashOfStrip(strip,stripWidth);
hash[hashValue] = StripId(row, index);
}
}
}
const Image& a_;
const Image& b_;
};
如果行完全匹配,则对两个图像中的行进行排序并合并。你的重复项就在那里。然后转到原始图像,并查找A中最长连续的重复项,使得B中相应的行也是连续的。或者只需查看相应图像的顶部和底部附近。
如果有横幅广告,首先想到的是将图像分成几个垂直条带,并分别处理每对条带。
类似下面这样的代码可能会有所帮助:
首先,从下往上遍历图像A,搜索其中有重要信息的行。例如,可以通过计算跨行的总颜色变化量来确定“信息”。比如,如果相邻的两个像素的颜色分别为#ffffff和#ff0000,则将2.0添加到总数中。准备一系列阈值,并锁定达到该阈值的第一行。这个系列可以是“10.0、0.1*行长度、0.15*行长度……”等等,直到一个合理的限制。然后,从最上面发现的位置向下遍历这个数组,取出相应的行并在B中从底部向上搜索其匹配项。如果找到了,并且阈值足够大,则取数组中的下一个并计算其匹配项的位置,进行比较。如果成功,就锁定了B相对于A的正确偏移量,它等于height_of_A - first_row_index + first_row_match_index。如果失败,则继续搜索下一行。如果所有匹配都失败了,则从A的最后一行开始,从B的第一行开始搜索,直到从A的底部找到的第一行的偏移量。如果再次失败,则答案为0。当然,如果使用JPEG图像,则使用阈值匹配,因为A和B中的像素可能不完全相同,也许还需要容忍不匹配的像素。