我在寻找一个类似但稍有不同的解决方案。如果对其他人有用的话,就在这里发布一下。
在我的情况下,我需要一个更通用的解决方案,允许每个字母重复任意次数。这是我想出来的:
library(tidyverse)
df <- data.frame(letters = letters[1:4])
df
> df
letters
1 a
2 b
3 c
4 d
假设我想要 2 个 A,3 个 B,2 个 C 和 4 个 D:
df %>%
mutate(count = c(2, 3, 2, 4)) %>%
group_by(letters) %>%
expand(count = seq(1:count))
# A tibble: 11 x 2
# Groups: letters [4]
letters count
<fctr> <int>
1 a 1
2 a 2
3 b 1
4 b 2
5 b 3
6 c 1
7 c 2
8 d 1
9 d 2
10 d 3
11 d 4
如果您不想保留计数列:
df %>%
mutate(count = c(2, 3, 2, 4)) %>%
group_by(letters) %>%
expand(count = seq(1:count)) %>%
select(letters)
letters
<fctr>
1 a
2 a
3 b
4 b
5 b
6 c
7 c
8 d
9 d
10 d
11 d
如果您希望计数反映每个字母重复出现的次数:
df %>%
mutate(count = c(2, 3, 2, 4)) %>%
group_by(letters) %>%
expand(count = seq(1:count)) %>%
mutate(count = max(count))
letters count
<fctr> <dbl>
1 a 2
2 a 2
3 b 3
4 b 3
5 b 3
6 c 2
7 c 2
8 d 4
9 d 4
10 d 4
11 d 4
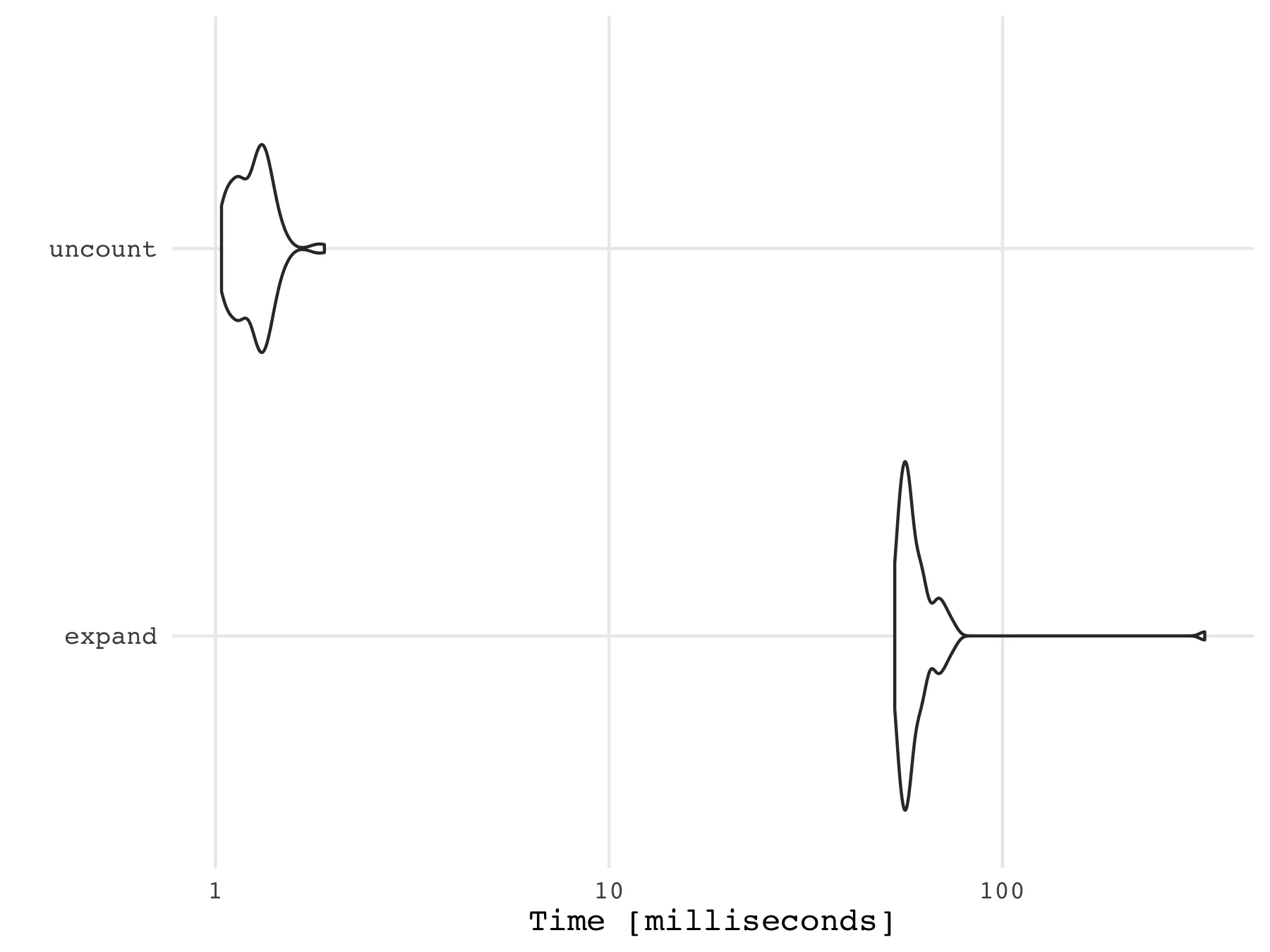
do块中,并从当前数据框生成一个新的数据框,就像这里所需的那样 (df %>% do(data.frame(column = rep(.$column, 4))))。然而,如果数据框有任何其他列,这种方法就会充满风险。 - r2evansdo(data.frame(a = rep(.$a, each=4)))即可。 - Alexander