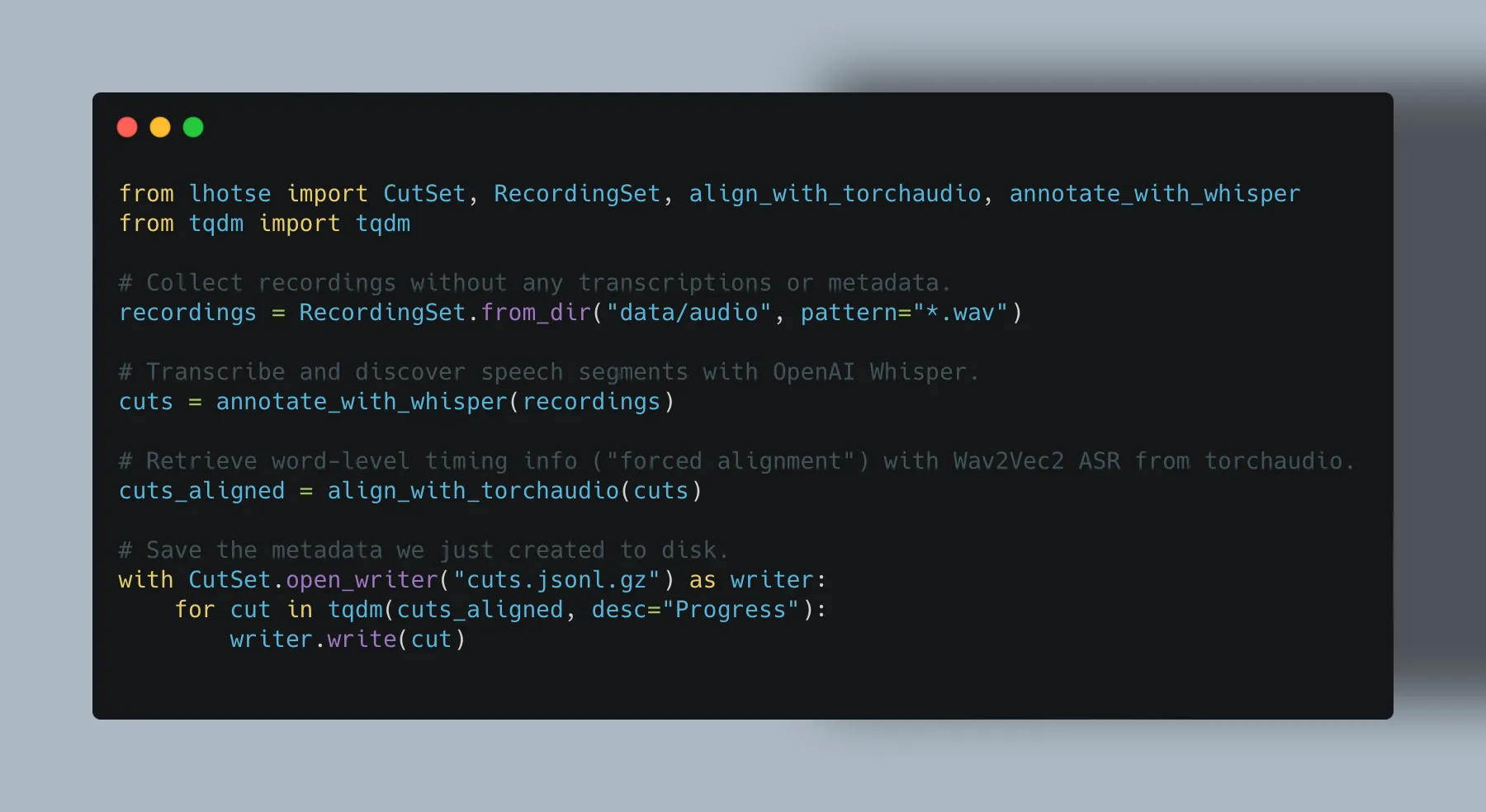
我使用OpenAI的Whisper Python库进行语音识别。如何获取单词级别的时间戳?
如果使用Nvidia GeForce RTX 3090,请在
使用OpenAI的Whisper进行转录(在Ubuntu 20.04 x64 LTS上测试,使用Nvidia GeForce RTX 3090):
conda create -y --name whisperpy39 python==3.9
conda activate whisperpy39
pip install git+https://github.com/openai/whisper.git
sudo apt update && sudo apt install ffmpeg
whisper recording.wav
whisper recording.wav --model large
如果使用Nvidia GeForce RTX 3090,请在
conda activate whisperpy39后添加以下内容:pip install -f https://download.pytorch.org/whl/torch_stable.html
conda install pytorch==1.10.1 torchvision torchaudio cudatoolkit=11.0 -c pytorch