我想要检查一个节点可以到达哪些节点。
因此,我想要提供一个图形和一个节点,并返回一个列表,其中包含可以从该节点到达图形的所有节点。(我知道有Data.Graph,但是我想从头开始理解它,并故意不使用它。)
为了构建图形,我获得了以下数据。
data Node = Node String [Node]
字符串只是节点名称的表示。
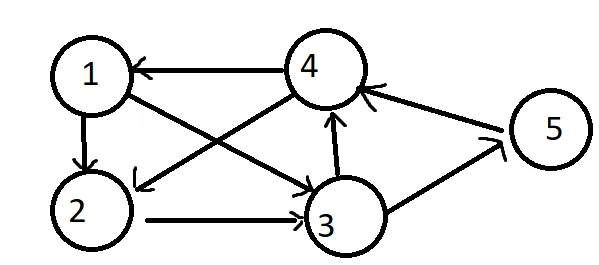
这是图形的表示方式。
node1 = Node "node1" [node2,node3]
node2 = Node "node2" [node3]
node3 = Node "node3" [node4,node5]
node4 = Node "node4" [node1,node2]
node5 = Node "node5" [node4]
我还获得了以下节点的(直接)到达:
canReachNext (Node x y) = y
我的基本想法是这样的:
listForReachables:: Node n => n -> [n]
listForReachables x
| contains[x] (canReachNext x) == False = listForReachables (head(canReachNext (x)))
| contains [x] (canReachNext x)== True = [x]
| otherwise = []
如果我运行,这会导致无限循环。
listForReachables node1
我明白为什么会进入循环了。因为在这个例子中,头部将总是有另一个列表。
我的问题和困惑之处在于,我习惯面向对象编程,在这种情况下,感觉需要一个列表来记住我已经检查过哪些节点,以及我还需要检查哪些节点。
reallyUnsafePtrEquality#这个函数,但请不要使用它。 - Joseph Sible-Reinstate Monica