我写了一个示例脚本,在重新安装Ubuntu 20.04后遇到了问题。似乎multiprocessing只使用了一个核心。以下是我的示例脚本:
以下是翻译的结果:
import random
from multiprocessing import Pool, cpu_count
def f(x): return x*x
if __name__ == '__main__':
with Pool(32) as p:
print(p.imap(f,random.sample(range(10, 99999999), 50000000)))
以下是翻译的结果:
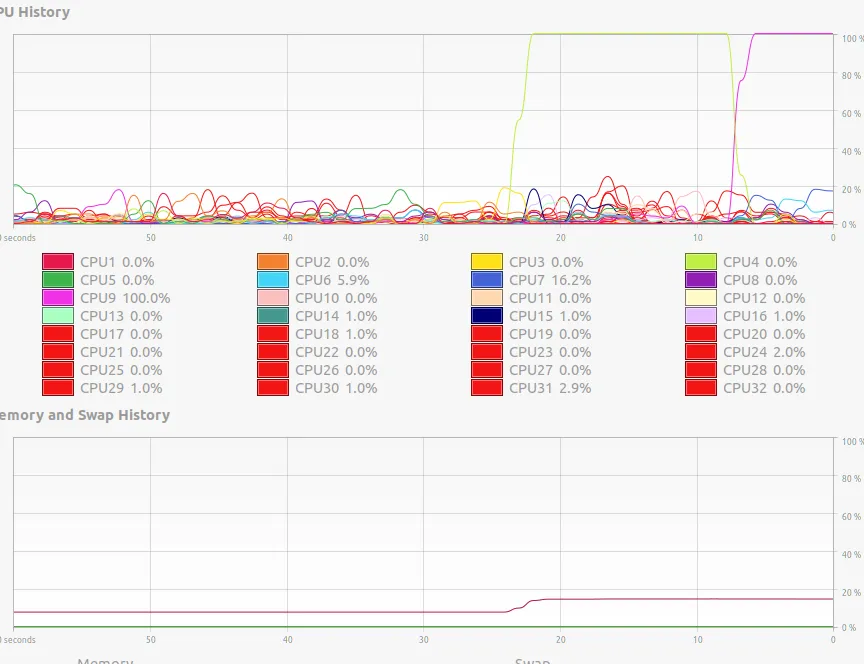
下面是我的处理过程的图像。有什么可能会导致这种情况?
chunksize参数。 - gold_cyf,例如def f(x): [x*x for _ in range(10**5)]。 - Andrey Khoronko