在Python3中,如何以最干净且最快的方式将所有“universal newlines”替换为b'\n',并得到一个bytes对象?
编辑:最终我使用了b'\n'.join(bytestr.splitlines()) ,因为它似乎是最安全的,而且我不介意把一行可能存在的换行符舍弃掉。
但是请看下面@norok2提供的优秀答案,其中包含了注意事项、时间和更快的解决方案。
在Python3中,如何以最干净且最快的方式将所有“universal newlines”替换为b'\n',并得到一个bytes对象?
编辑:最终我使用了b'\n'.join(bytestr.splitlines()) ,因为它似乎是最安全的,而且我不介意把一行可能存在的换行符舍弃掉。
但是请看下面@norok2提供的优秀答案,其中包含了注意事项、时间和更快的解决方案。
有点晚了,但让我们看看我能做出什么贡献。
首先要声明的是:我的最爱是@JohnHennig的双.replace()方法,因为它速度合理,并且清晰明了。
我认为在标准Python中,除了其他答案已经提出的方法(其中一些我稍微修改以获得与双重.replace()完全相同的结果)之外,没有其他简单和快速的解决方案。
然而,可能有可能加速。这里我提出了3个额外的解决方案:两个使用Cython,一个使用Numba。
为了简单起见,我使用IPython和Cython魔法写了这篇文章。
%load_ext Cython
核心思想是只需要在遍历输入时将数据复制到另一个字符串中,因此只需要遍历一次即可。
直接在Python中编写这段代码很简单,但为了使其可行,我们需要使用 bytearray() 来克服 str / bytes 的不可变性。可以使用Cython将这个慢循环编译成速度更快的版本 (unl_loop_cy())。
%%cython -c-O3 -c-march=native -a
#cython: language_level=3, boundscheck=False, wraparound=False, initializedcheck=False, cdivision=True, infer_types=True
def unl_loop_cy(b):
nl_cr = b'\r'[0]
nl_lf = b'\n'[0]
n = len(b)
result = bytearray(n)
i = j = 0
while i + 1 <= n:
if b[i] == nl_cr:
result[j] = nl_lf
i += 2 if b[i + 1] == nl_lf else 1
else:
result[j] = b[i]
i += 1
j += 1
return bytes(result[:j])
然而,既不是bytes也不是bytearray与Numba兼容。
要使用它,我们需要通过NumPy进行处理,NumPy提供了有效处理bytes的方法:np.frombuffer()和np.ndarray.tobytes()。
基本算法保持不变,代码现在如下:
import numpy as np
import numba as nb
@nb.jit
def _unl_loop_nb(b, result):
nl_cr = b'\r'[0]
nl_lf = b'\n'[0]
n = len(b)
i = j = 0
while i + 1 <= n:
if b[i] == nl_cr:
result[j] = nl_lf
i += 2 if b[i + 1] == nl_lf else 1
else:
result[j] = b[i]
i += 1
j += 1
return j
def unl_loop_nb(b):
arr = np.frombuffer(b, np.uint8)
result = np.empty(arr.shape, np.uint8)
size = _unl_loop_nb(arr, result)
return result[:size].tobytes()
使用更新版本的Numba,支持bytes和np.empty(),可以编写改进版如下:
import numpy as np
import numba as nb
@nb.jit
def _unl_loop_nb2(b):
nl_cr = b'\r'[0]
nl_lf = b'\n'[0]
n = len(b)
result = np.empty(n, dtype=np.uint8)
i = j = 0
while i + 1 <= n:
if b[i] == nl_cr:
result[j] = nl_lf
i += 2 if b[i + 1] == nl_lf else 1
else:
result[j] = b[i]
i += 1
j += 1
return result[:j]
def unl_loop_nb2(b):
return _unl_loop_nb2(b).tobytes()
最后,我们可以进一步优化Cython解决方案,以获得额外的速度。为此,我们将 bytearray 替换为实际的C++字符串,并尽可能多地将计算“推到Python之外”。
%%cython --cplus -c-O3 -c-march=native -a
#cython: language_level=3, boundscheck=False, wraparound=False, initializedcheck=False, cdivision=True, infer_types=True
from libcpp.string cimport string
cdef extern from *:
"""
#include <string>
std::string & erase(
std::string & s,
std::size_t pos,
std::size_t len) {
return s.erase(pos, len); }
"""
string& erase(string& s, size_t pos, size_t len)
cpdef string _unl_cppstr_cy(string s):
cdef char nl_lf = b'\n'
cdef char nl_cr = b'\r'
cdef char null = b'\0'
cdef size_t s_size = s.size()
cdef string result = string(s_size, null)
cdef size_t i = 0
cdef size_t j = 0
while i + 1 <= s_size:
if s[i] == nl_cr:
result[j] = nl_lf
if s[i + 1] == nl_lf:
i += 1
else:
result[j] = s[i]
j += 1
i += 1
return erase(result, j, i - j)
def unl_cppstr_cy(b):
return _unl_cppstr_cy(b)
针对Numba情况下,C++优化解决方案和Numba加速方法的效率相当有竞争力,它们都优于双重.replace()方法(对于Numba情况下足够大的输入)。对于一些较小的输入,C++优化方法是最快的,但对于足够大的输入,基于Numba的方法(特别是第二种)会变得更快。考虑到Cython编译,通过循环实现的Cython加速bytearray方法在测试中表现最慢,但与其他解决方案相比也具有一定的竞争力。
测试结果如下所示:
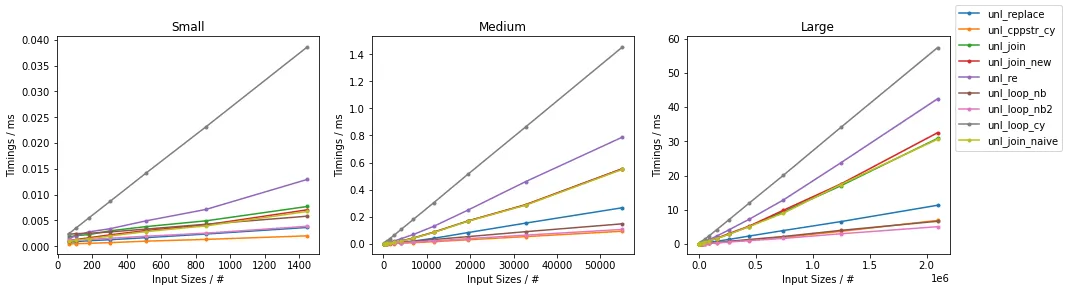
并且,最快方法的缩放图如下所示:
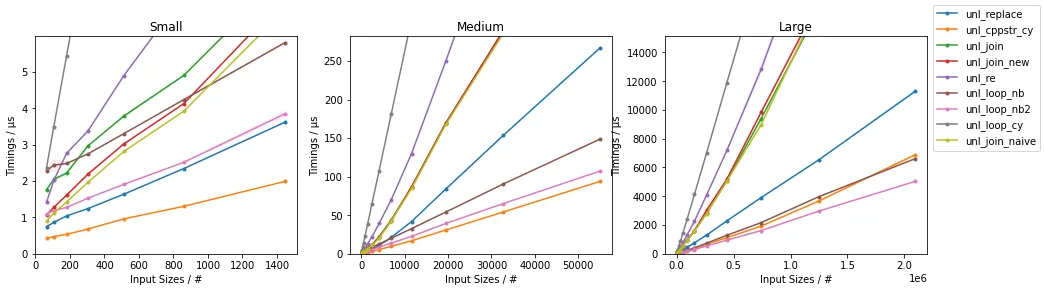
为了完整起见,这里列出了其他测试过的函数:
def unl_replace(s):
return s.replace(b'\r\n', b'\n').replace(b'\r', b'\n')
# EDIT: was originally the commented code, but it is less efficient
# def unl_join(s):
# nls = b'\r\n', b'\r', b'\n'
# return b'\n'.join(s.splitlines()) + (
# b'\n' if any(s.endswith(nl) for nl in nls) else b'')
def unl_join(s):
result = b'\n'.join(s.splitlines())
nls = b'\r\n', b'\r', b'\n'
if any(s.endswith(nl) for nl in nls):
result += b'\n'
return result
# Following @VPfB suggestion
def unl_join_new(s):
return b'\n'.join((s + b'\0').splitlines())[:-1]
import re
def unl_re(s, match=re.compile(b'\r\n?')):
return match.sub(b'\n', s)
def unl_join_naive(s): # NOTE: not same result as `unl_replace()`
return b'\n'.join(s.splitlines())
这是用于生成输入的函数:
def gen_input(num, nl_factor=0.10):
nls = b'\r\n', b'\r', b'\n'
words = (b'a', b'b', b' ')
random.seed(0)
nl_percent = int(100 * nl_factor)
base = words * (100 - nl_percent) + nls * nl_percent
return b''.join([base[random.randint(0, len(base) - 1)] for _ in range(num)])
我还测试了一些显式循环的其他实现方法,但由于它们比提议的解决方案慢了数个数量级(即使使用Cython编译后计时也更慢),所以我已将其从比较结果中省略,但我在此报告它们以供参考:
def unl_loop(b):
nl_cr = b'\r'[0]
nl_lf = b'\n'[0]
n = len(b)
result = bytearray(n)
i = j = 0
while i + 1 <= n:
if b[i] == nl_cr:
result[j] = nl_lf
i += 2 if b[i + 1] == nl_lf else 1
else:
result[j] = b[i]
i += 1
j += 1
return bytes(result[:j])
def unl_loop_add(b):
nl_cr = b'\r'[0]
nl_lf = b'\n'[0]
result = b''
i = 0
while i + 1 <= len(b):
if b[i] == nl_cr:
result += b'\n'
i += 2 if b[i + 1] == nl_lf else 1
else:
result += b[i:i + 1]
i += 1
return result
def unl_loop_append(b):
nl_cr = b'\r'[0]
nl_lf = b'\n'[0]
result = bytearray()
i = 0
while i + 1 <= len(b):
if b[i] == nl_cr:
result.append(nl_lf)
i += 2 if b[i + 1] == nl_lf else 1
else:
result.append(b[i])
i += 1
return bytes(result)
def unl_loop_del(b):
nl_cr = b'\r'[0]
nl_lf = b'\n'[0]
b = bytearray(b)
i = 0
while i + 1 <= len(b):
if b[i] == nl_cr:
if b[i + 1] == nl_lf:
del b[i]
else:
b[i] = nl_lf
i += 1
return bytes(b)
(编辑:关于假设/潜在问题的评论)
对于"混合换行符"文件,例如b'alpha\nbravo\r\ncharlie\rdelta',理论上会存在一个不确定性,即是否将\r\n视为1个或2个换行符。
以上实现的所有方法都将具有相同的行为,并将\r\n视为单个换行符。
此外,所有这些方法都将在复杂编码中出现\r和/或\r\n的误报问题,例如,从@JohnHennig的评论中得知,马拉雅拉姆文ഊ的字母在UTF-16中编码为b'\r\n',并且bytes.splitlines()似乎没有意识到这一点,所有测试过的方法看起来都具有相同的行为:
s = 'ഊ\n'.encode('utf-16')
print(s)
# b'\xff\xfe\n\r\n\x00'
s.splitlines()
[b'\xff\xfe', b'', b'\x00']
for func in funcs:
print(func(s))
# b'\xff\xfe\n\n\x00'
# b'\xff\xfe\n\n\x00'
# b'\xff\xfe\n\n\x00'
# b'\xff\xfe\n\n\x00'
# b'\xff\xfe\n\n\x00'
# b'\xff\xfe\n\n\x00'
最后,unl_join_naive() 只依赖于Python实现的行拆分,这意味着它的结果不太明显,但是未来可能会对这些问题提供更好的支持。
如果字符串末尾有换行符,则该方法还会删除末尾的换行符,因此需要一些额外的代码(通常只需要一个小的恒定偏移量)来克服这种行为。解决此问题的几个建议包括:
bytes.splitlines() 实现中是没有问题的,但如果出现误报的\r\n 并且 bytes.splitlines() 对此变得敏感时,这可能成为问题),如 unl_join() 中所示;\0)到原始输入,并在 join() 后删除最后一个元素(这似乎比前面的方法更安全、更快),如 unl_join_new() 中所示。(编辑:添加了一个更简单的Cython解决方案,一个基于Numba的解决方案并更新时间。
(编辑:添加另一个基于Numba的解决方案,需要支持bytes和np.empty(),并更新时间)。
join(不检查最后一个换行符)呢?只是为了进行比较。 - user124114unl_join()函数,同时也评论了一些关于外来编码的问题。 - norok2这是我过去所使用的:
>>> bytestr = b'A sentence\rextending over\r\nmultiple lines.\n'
>>> bytestr.replace(b'\r\n', b'\n').replace(b'\r', b'\n')
b'A sentence\nextending over\nmultiple lines.\n'
我不知道它是否是最好的方法,但它很直接且易于理解。例如,替换双字节序列首先,然后再替换剩余的孤立\r字符,这一点非常重要。
尽管上面的示例混合了不同类型的换行符字节序列,但假设该方法仅用于使用相同换行符的输入,这是一个隐含的假设。它只是对可能出现的任何换行符不可知。例如:b'\r\r\n\n'如果允许混合换行符,则没有唯一的解释,因为它可以代表3或4个空行。
b'\n'.join(bytes.splitlines()) 不是更安全吗? - user124114splitlines()会删除末尾的换行符(如果有的话),因此您在这里的解决方案可能更可取(取决于您是否想保留最后的换行符)。 - user124114splitlines/join对\r\r\n\n会产生什么影响吗?除此之外,我不认为会有任何新的换行符编码出现(如果有的话——我们已经从痛苦的经历中学到了教训,ASCII标准也没有提供太多空间,而唯一剩下的选择\n\r会使混合换行符文件变得过于模糊),因此我不认为有太多的空间来保证未来的兼容性。 - norok2正则表达式也可以用于处理 bytes 对象。那么下面这个怎么做呢:
import re
data = b"hello\r\n world\r\naaaaa\rbbbbbb"
print(re.sub(b"\r\n?",b"\n",data))
结果:
b'hello\n world\naaaaa\nbbbbbb'
\r,后面可以跟随\n并将其替换为\n。正则表达式覆盖了所有情况,并且只需要1次操作即可完成。从我的测试结果来看,仅进行两次bytes.replace如约翰的答案所示会更快。b'\n'.join(bytestr.splitlines())
bytes.splitlines() 内置函数似乎比多次调用 bytes.replace() 更安全、更快:
bytestr = b'A sentence\rextending over\r\nmultiple lines.\n'
timeit b'\n'.join(bytestr.splitlines())
385 ns ± 21.7 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
timeit bytestr.replace(b'\r\n', b'\n').replace(b'\r', b'\n')
457 ns ± 14.8 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
它具有更好的可靠性,以防“通用换行符”行为在Python未来版本中再次发生变化。
它会删除末尾的换行符(如果有)。
bytes.splitlines 的地方。 (我认为UTF-16和UTF-32是这样的例外情况)。 - VPfB