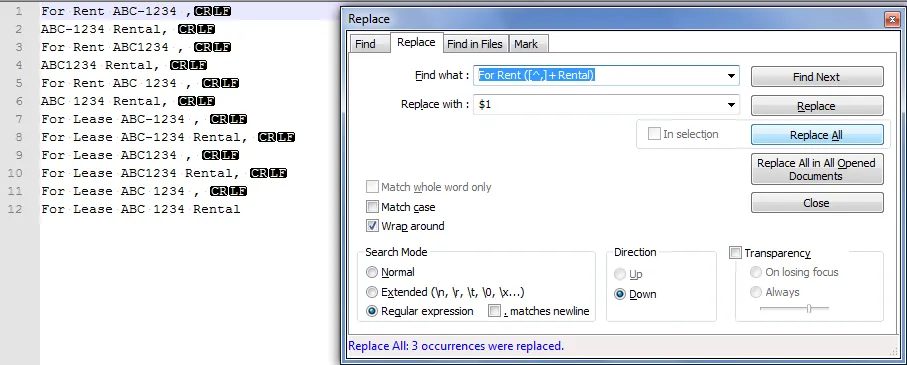
我有一个以CSV文件格式导出的元关键词列表
例如:
For Rent ABC-1234 , For Rent ABC-1234 Rental, For Rent ABC1234 , For Rent ABC1234 Rental, For Rent ABC 1234 , For Rent ABC 1234 Rental, For Lease ABC-1234 , For Lease ABC-1234 Rental, For Lease ABC1234 , For Lease ABC1234 Rental, For Lease ABC 1234 , For Lease ABC 1234 Rental
我希望做的是将“出租XXX租赁”的值中的“出租”文字移除,这样剩下的值就只读作“XXX租赁”。
这可以使用正则表达式来实现吗?