有两种一般的(“Excel”/“本地”/非应用脚本)解决方案来返回正则表达式匹配项的数组,以REGEXEXTRACT的方式:
方法1)
在匹配项周围插入分隔符,删除垃圾,并调用SPLIT
正则表达式通过从左到右迭代字符串并“消耗”来工作。如果我们小心地消耗垃圾值,我们可以将它们丢弃。
(这避免了当前接受的解决方案面临的问题,即如Carlos Eduardo Oliveira所提到的,如果语料库文本包含特殊的正则表达式字符,则显然会失败。)
首先,我们要选定一个分隔符,它必须在文本中不存在。正确的做法是解析文本并临时替换我们的分隔符为“临时分隔符”,例如如果我们要使用逗号",",我们首先将所有现有的逗号替换为"<<QUOTED-COMMA>>",然后再取消替换。但是,为了简单起见,我们将从私人使用的Unicode块(private-use unicode blocks)中选择一个随机字符作为我们的特殊分隔符,例如(注意它是2个字节...谷歌电子表格可能无法以一致的方式计算字形中的字节,但我们稍后会小心处理)。
=SPLIT(
LAMBDA(temp,
MID(temp, 1, LEN(temp)-LEN(""))
)(
REGEXREPLACE(
"xyzSixSpaces:[ ]123ThreeSpaces:[ ]aaaa 12345",".*?( |$)",
"$1"
)
),
""
)
我们只需使用lambda定义temp="match1match2match3",然后使用它将最后一个分隔符删除为"match1match2match3",然后SPLIT它。
对结果进行COLUMNS操作将证明返回了正确的结果,即{" ", " ", " "}。
这是一个特别好的函数可以转换为命名函数,并将其命名为REGEXGLOBALEXTRACT(text,regex)或REGEXALLEXTRACT(text,regex),例如:
=SPLIT(
LAMBDA(temp,
MID(temp, 1, LEN(temp)-LEN(""))
)(
REGEXREPLACE(
text,
".*?("®ex&"|$)",
"$1"
)
),
""
)
方法二)
使用递归
使用LAMBDA(即像其他编程语言一样定义函数)可以使用lambda演算和函数式编程中的一些技巧:你可以访问递归。定义递归函数很困惑,因为没有简单的方式让它引用自身,所以必须使用一个技巧/约定:
递归函数的技巧:实际上定义一个需要引用其自身的函数f,而是定义一个具有参数itself并返回您实际想要的函数的函数;将此“约定”传递给Y-combinator,使其转化为实际递归函数。
管道采取这种功能的技术被称为Y组合子。如果您具有一些编程背景,这是一个好的文章
good article to understand it。
举个例子,要得到5的阶乘(即实现我们自己的FACT(5)),我们可以定义:
命名函数Y(f)=LAMBDA(f, (LAMBDA(x,x(x)))( LAMBDA(x, f(LAMBDA(y, x(x)(y)))) ) )(这是Y组合器,很神奇;你不必理解它就能使用它)
命名函数MY_FACTORIAL(n)=
Y(LAMBDA(self,
LAMBDA(n,
IF(n=0, 1, n*self(n-1))
)
))
MY_FACTORIAL(5)的结果为:120
Y组合子使得编写递归函数看起来相对容易,就像编程课程的入门一样。我使用命名函数以增加清晰度,但你也可以将它们全部混在一起,只是会牺牲一些理智...
=LAMBDA(Y,
Y(LAMBDA(self, LAMBDA(n, IF(n=0,1,n*self(n-1))) ))(5)
)(
LAMBDA(f, (LAMBDA(x,x(x)))( LAMBDA(x, f(LAMBDA(y, x(x)(y)))) ) )
)
这如何应用于手头的问题?递归解决方案如下所示:
在下面的伪代码中,我使用“function”代替
LAMBDA,但它是相同的东西:
function emptyList() {
return {"ignore this value"}
}
function listToArray(myList) {
return OFFSET(myList,0,1)
}
function allMatches(text, regex) {
allMatchesHelper(emptyList(), text, regex)
}
function allMatchesHelper(resultsToReturn, text, regex) {
currentMatch = REGEXEXTRACT(...)
if (currentMatch succeeds) {
textWithoutMatch = SUBSTITUTE(text, currentMatch, "", 1)
return allMatches(
{resultsToReturn,currentMatch},
textWithoutMatch,
regex
)
} else {
return listToArray(resultsToReturn)
}
}
很遗憾,递归方法的增长阶数是二次的(因为它一遍又一遍地将结果附加到自身上,同时使用较小的字符串片段重建巨大的搜索字符串,所以 1+2+3+4+5+... = big^2,这可能需要很长时间),所以如果你有很多匹配项的话,可能会变得很慢。为了速度起见,最好在正则表达式引擎内部保持,因为它很可能经过高度优化。
当然,你可以通过使用 LAMBDA(varName, expr)(varValue) 进行临时绑定来避免使用命名函数,如果你想在表达式中使用 varName。(你可以将该模式定义为一个命名函数 =cont(varValue),以倒转参数顺序以保持代码更清晰,也可以不这样做。)
- 每当我使用
varName = varValue,就写成那样。
- 要检查匹配是否成功,使用
ISNA(...)
它会看起来像这样:
命名函数 allMatches(resultsToReturn, text, regex):
未经测试:
LAMBDA(helper,
OFFSET(
helper({"ignore"}, text, regex),
0,1)
)(
Y(LAMBDA(helperItself,
LAMBDA(results, partialText,
LAMBDA(currentMatch,
IF(ISNA(currentMatch),
results,
LAMBDA(textWithoutMatch,
helperItself({results,currentMatch}, textWithoutMatch)
)(
SUBSTITUTE(partialText, currentMatch, "", 1)
)
)
)(
REGEXEXTRACT(partialText, regex)
)
)
))
)
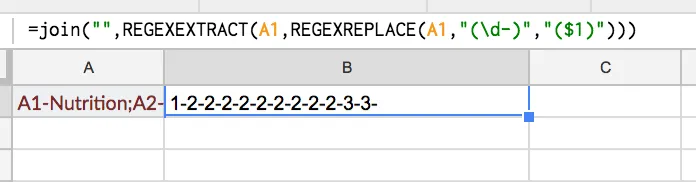
((\d-)),我会得到前两个匹配项,使用(((\d-)))我会得到前三个,但如何获取它们所有,不知道有多少个?也许使用组名\1,允许任何匹配重复,用.*分隔...或者至少通过组合多个REGEXEXTRACT和/或REGEXREPLACE公式。 - flo5783(?g),它适用于某些re flavor但不适用于re2。这是一个很棒的问题。 - dawg=regexreplace(A1,"(\d-)|.","$1")到目前为止是最好的,谢谢!简单高效 :) - flo5783