只是为了记录,使用gnuplot 单独 的方式可以从两个文件中获取最大值。
当然,使用Linux工具或在Windows安装例如GnuWin的CoreUtils可能更有效率,但是使用gnuplot-only,则可以确保平台无关,不需要额外的安装。
假设:两个文件具有相同的行数和相同的x值。
编辑:简化代码适用于所有gnuplot版本>=4.6.0,而对于gnuplot>=5.2.0则使用数组的更快速版本。
一个简单的“技巧”是将一个文件的y值写入单个字符串,并通过word()进行寻址。对于小数据,这样做没问题,但对于大数据(>10'000行),它可能会变慢,因为它似乎运行了类似O(N^2)的东西。只是为了让你有个概念(在我的系统上):1'000行需要0.4秒,10'000行需要13秒,而20'000行已经需要45秒。
相比之下,gnuplot>=5.2.0的数组解决方案仅需要约3秒钟来处理10'000行。
数据:
SO19079146_1.dat
1 1.1
2 2.1
4 1.5
6 1.3
7 0.2
8 1.5
9 2.1
SO19079146_2.dat
1 2.1
2 2.5
4 1.5
6 0.3
7 0.7
8 1.0
9 1.4
脚本1:(适用于gnuplot>=4.6.0,2012年3月)
reset
FILE1 = 'SO19079146_1.dat'
FILE2 = 'SO19079146_2.dat'
data2 = ''
stats FILE2 u (data2=data2.' '.sprintf("%g",$2)) nooutput
set offset 1,1,1,1
max(col) = (i=int(column(0)+1), y1=column(col), y2=real(word(data2,i)), y1>y2 ? y1 : y2)
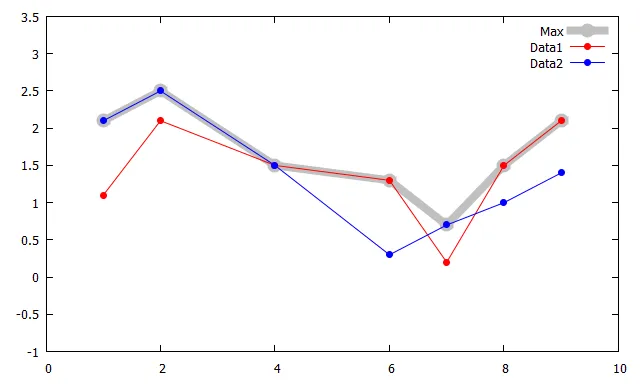
plot FILE1 u 1:(max(2)) w lp pt 7 lw 8 lc rgb "grey" ti "Max", \
'' u 1:2 w lp pt 7 lc rgb "red" ti "Data1", \
FILE2 u 1:2 w lp pt 7 lc rgb "blue" ti "Data2"
脚本2:(适用于gnuplot>=5.2.0,2017年9月)
reset session
FILE1 = 'SO/SO19079146_1.dat'
FILE2 = 'SO/SO19079146_2.dat'
stats FILE1 u 0 nooutput
array A[STATS_records]
stats FILE2 u (i=int($0+1), A[i]=$2) nooutput
set offset 1,1,1,1
max(col) = (i=int(column(0)+1), y1=column(col), y2=A[i], y1>y2 ? y1 : y2)
plot FILE1 u 1:(max(2)) w lp pt 7 lw 8 lc "grey" ti "Max", \
'' u 1:2 w lp pt 7 lc "red" ti "Data1", \
FILE2 u 1:2 w lp pt 7 lc "blue" ti "Data2"
结果:(对于以上所有版本均相同)
python脚本,它可能比使用paste更具平台独立性,请参见编辑部分。 - Christoph