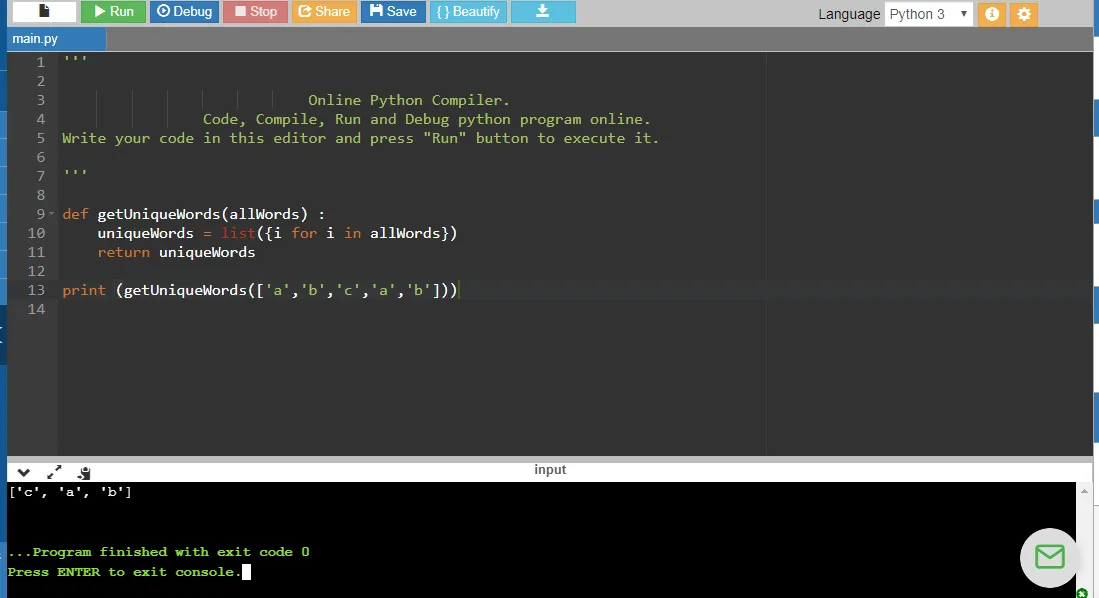
我正在尝试根据从文本文件中提取的所有单词列表创建唯一单词列表。 我唯一的问题是用于迭代两个列表的算法。
def getUniqueWords(allWords):
uniqueWords = []
uniqueWords.append(allWords[0])
for i in range(len(allWords)):
for j in range(len(uniqueWords)):
if allWords[i] == uniqueWords[j]:
pass
else:
uniqueWords.append(allWords[i])
print uniqueWords[j]
print uniqueWords
return uniqueWords
如您所见,我创建了一个空列表,并开始迭代两个列表。同时,我附加了列表中的第一项,因为由于某些原因它不会尝试匹配单词。毕竟,在空列表中,list [0] 不存在。如果有人能帮助我解决如何正确迭代它,以便我可以生成单词列表,那将非常好。
打印uniqueWords [j] 只是用来进行调试,以便我在处理列表时能够看到输出内容。