快速分析测试的结果为:
Java 类:
public class Main {
private static native int zero();
private static int testNative() {
return Main.zero();
}
private static int test() {
return 0;
}
public static void main(String[] args) {
testNative();
test();
}
static {
System.loadLibrary("foo");
}
}
C库:
#include <jni.h>
#include "Main.h"
JNIEXPORT int JNICALL
Java_Main_zero(JNIEnv *env, jobject obj)
{
return 0;
}
结果:
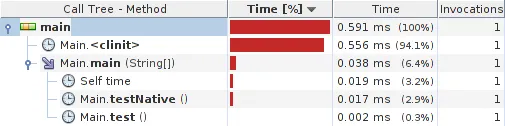
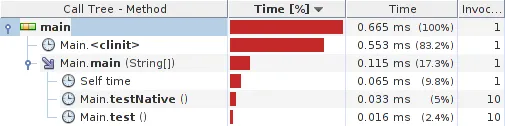
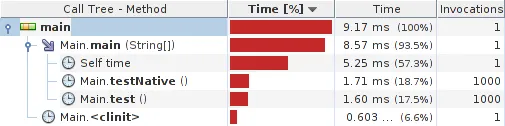
系统详情:
java version "1.7.0_09"
OpenJDK Runtime Environment (IcedTea7 2.3.3) (7u9-2.3.3-1)
OpenJDK Server VM (build 23.2-b09, mixed mode)
Linux visor 3.2.0-4-686-pae #1 SMP Debian 3.2.32-1 i686 GNU/Linux
更新: Caliper 微基准测试适用于 x86 (32/64 位) 和 ARMv6:
Java 类:
public class Main extends SimpleBenchmark {
private static native int zero();
private Random random;
private int[] primes;
public int timeJniCall(int reps) {
int r = 0;
for (int i = 0; i < reps; i++) r += Main.zero();
return r;
}
public int timeAddIntOperation(int reps) {
int p = primes[random.nextInt(1) + 54];
for (int i = 0; i < reps; i++) p += i;
return p;
}
public long timeAddLongOperation(int reps) {
long p = primes[random.nextInt(3) + 54];
long inc = primes[random.nextInt(3) + 4];
for (int i = 0; i < reps; i++) p += inc;
return p;
}
@Override
protected void setUp() throws Exception {
random = new Random();
primes = getPrimes(1000);
}
public static void main(String[] args) {
Runner.main(Main.class, args);
}
public static int[] getPrimes(int limit) {
}
static {
System.loadLibrary("foo");
}
}
结果(x86/i7500/Hotspot/Linux):
Scenario{benchmark=JniCall} 11.34 ns
Scenario{benchmark=AddIntOperation} 0.47 ns
Scenario{benchmark=AddLongOperation} 0.92 ns
benchmark ns linear runtime
JniCall 11.335 ==============================
AddIntOperation 0.466 =
AddLongOperation 0.921 ==
结果(amd64 / Phenom 960T / Hostspot / Linux):
Scenario{benchmark=JniCall} 6.66 ns
Scenario{benchmark=AddIntOperation} 0.29 ns
Scenario{benchmark=AddLongOperation} 0.26 ns
benchmark ns linear runtime
JniCall 6.657 ==============================
AddIntOperation 0.291 =
AddLongOperation 0.259 =
结果 (armv6/BCM2708/Zero/Linux):
Scenario{benchmark=JniCall} 678.59 ns
Scenario{benchmark=AddIntOperation} 183.46 ns
Scenario{benchmark=AddLongOperation} 199.36 ns
benchmark ns linear runtime
JniCall 679 ==============================
AddIntOperation 183 ========
AddLongOperation 199 ========
简单概括一下,似乎 JNI 调用在典型的 (x86) 硬件和 Hotspot VM 上大约相当于 10-25 次 java 操作。毫不意外,在优化程度远低于 Zero VM 的情况下,结果会有很大差异(3-4次操作)。
感谢 @Giovanni Azua 和 @Marko Topolnik 的参与和提示。