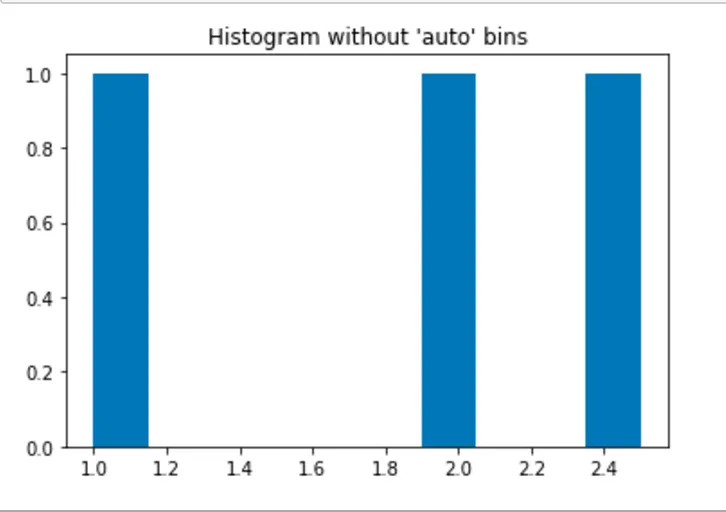
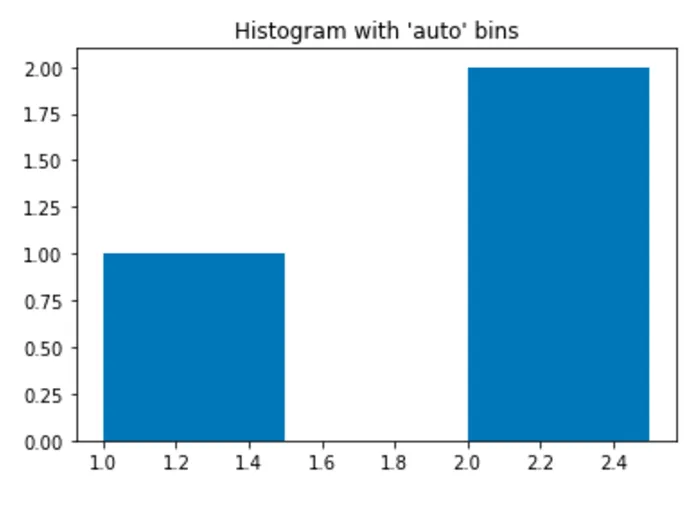
我正在尝试制作一个直方图,这个直方图是基于包含浮点数的文本文件创建的:
import matplotlib.pyplot as plt
c1_file = open('densEst1.txt','r')
c1_data = c1_file.read().split()
c1_sum = float(c1_data.__len__())
plt.hist(c1_data)
plt.show()
c1_data.__len__() 的输出正常,但是 hist() 出错了:
C:\Python27\python.exe "C:/x.py"
Traceback (most recent call last):
File "C:/x.py", line 7, in <module>
plt.hist(c1_data)
File "C:\Python27\lib\site-packages\matplotlib\pyplot.py", line 2958, in hist
stacked=stacked, data=data, **kwargs)
File "C:\Python27\lib\site-packages\matplotlib\__init__.py", line 1812, in inner
return func(ax, *args, **kwargs)
File "C:\Python27\lib\site-packages\matplotlib\axes\_axes.py", line 5995, in hist
if len(xi) > 0:
TypeError: len() of unsized object