我正在运行一个R程序,计算产品描述之间的相似度。程序的输入是一个文件,其中有1列,包含产品描述的列表,每个描述占一行。
我还有另一个文件,其中包含产品标题的列表,每个标题占一行。
使用dist函数,我已经计算了产品描述之间的相似度,并将它们存储在dist.mat矩阵中。
接下来,我想把产品标题与我计算出的相似度进行合并。所以,我读取了Names中的产品标题,然后:
然后我收到一个错误: Error in data.frame(dist.mat, row.names = Names[, 1]) : row names supplied are of the wrong length
不太确定如何解决。我阅读了这篇文章:Invalid 'row.names' length,但我不能使用Sample$或as.character修复错误。
我正在使用:lsa_0.73,SnowballC_0.5.1,tm_0.5-10。
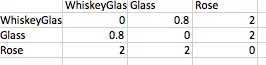
这里是一个实际的例子: 产品描述文件:
我还有另一个文件,其中包含产品标题的列表,每个标题占一行。
使用dist函数,我已经计算了产品描述之间的相似度,并将它们存储在dist.mat矩阵中。
接下来,我想把产品标题与我计算出的相似度进行合并。所以,我读取了Names中的产品标题,然后:
dist.mat <- data.frame(dist.mat, row.names=Names[,1])
colnames(dist.mat) <- (row.names(dist.mat))
然后我收到一个错误: Error in data.frame(dist.mat, row.names = Names[, 1]) : row names supplied are of the wrong length
不太确定如何解决。我阅读了这篇文章:Invalid 'row.names' length,但我不能使用Sample$或as.character修复错误。
我正在使用:lsa_0.73,SnowballC_0.5.1,tm_0.5-10。
这里是一个实际的例子: 产品描述文件:
- 这个玻璃杯可以用来喝威士忌。
- 这是一个不锈钢杯子。
- 这是一朵红玫瑰。
- Whiskeyglass
- glass
- rose
{kind=link}