当分析表格时,加密和解密之间的差异是否意味着我的实现异常缓慢?我做错了什么吗?三到四件事情引起了我的注意。我有点同意@JamesKPolk的看法-数字看起来不对。首先,加密库通常使用CTR模式而不是CBC模式进行基准测试。还可以参见
SUPERCOP benchmarks。您必须使用每字节周期(cpb)来规范化跨机器的测量单位。没有上下文地说“9 MB / s”毫无意义。
其次,我们需要了解机器及其CPU频率。看起来您正在进行9 MB/s的加密和6.5 MB/s的解密数据推送。像
2.7 GHz运行的Core-i5这样的现代iCore机器将以大约2.5或3.0 cpb的速度推动CBC模式数据,大约为980 MB/s或1 GB/s。即使是我旧的
2.0 GHz运行的Core2 Duo也比您展示的速度更快。Core 2以14.5 cpb或130 MB/s的速度移动数据。
第三,废弃此代码。它有很大的改进空间,因此在此上下文中不值得批评;建议使用的代码如下。值得一提的是,您正在创建许多对象,例如
ArraySource和
StreamTransformationFilter。该过滤器添加填充会干扰AES加密和解密基准测试并扭曲结果。您只需要一个加密对象,然后只需调用
ProcessBlock或
ProcessString。
CryptoPP::AES::Decryption aesDecryption(aesKey, ENCRYPTION_KEY_SIZE_AES);
CryptoPP::CBC_Mode_ExternalCipher::Decryption cbcDecryption(aesDecryption, aesIv);
...
第四,Crypto++维基有一篇基准测试文章,其中包含以下代码。这是一个新的部分,在你提出问题时还没有。以下是如何运行您的测试。
AutoSeededRandomPool prng;
SecByteBlock key(16);
prng.GenerateBlock(key, key.size());
CTR_Mode<AES>::Encryption cipher;
cipher.SetKeyWithIV(key, key.size(), key);
const int BUF_SIZE = RoundUpToMultipleOf(2048U,
dynamic_cast<StreamTransformation&>(cipher).OptimalBlockSize());
AlignedSecByteBlock buf(BUF_SIZE);
prng.GenerateBlock(buf, buf.size());
const double runTimeInSeconds = 3.0;
const double cpuFreq = 2.7 * 1000 * 1000 * 1000;
double elapsedTimeInSeconds;
unsigned long i=0, blocks=1;
ThreadUserTimer timer;
timer.StartTimer();
do
{
blocks *= 2;
for (; i<blocks; i++)
cipher.ProcessString(buf, BUF_SIZE);
elapsedTimeInSeconds = timer.ElapsedTimeAsDouble();
}
while (elapsedTimeInSeconds < runTimeInSeconds);
const double bytes = static_cast<double>(BUF_SIZE) * blocks;
const double ghz = cpuFreq / 1000 / 1000 / 1000;
const double mbs = bytes / 1024 / 1024 / elapsedTimeInSeconds;
const double cpb = elapsedTimeInSeconds * cpuFreq / bytes;
std::cout << cipher.AlgorithmName() << " benchmarks..." << std::endl;
std::cout << " " << ghz << " GHz cpu frequency" << std::endl;
std::cout << " " << cpb << " cycles per byte (cpb)" << std::endl;
std::cout << " " << mbs << " MiB per second (MiB)" << std::endl;
在一台主频为2.7 GHz的Core-i5 6400上运行代码会得到以下结果:
$ ./bench.exe
AES/CTR benchmarks...
2.7 GHz cpu frequency
0.58228 cycles per byte (cpb)
4422.13 MiB per second (MiB)
第五步,当我修改上面展示的基准程序以操作64字节块时:
const int BUF_SIZE = 64;
unsigned int blocks = 0;
...
do
{
blocks++;
cipher.ProcessString(buf, BUF_SIZE);
elapsedTimeInSeconds = timer.ElapsedTimeAsDouble();
}
while (elapsedTimeInSeconds < runTimeInSeconds);
我看到Core-i5 6400在2.7 GHz时,64字节块的速度为3.4 cpb或760 MB/s。对于小缓冲区,该库会受到影响,但大多数(全部?)库都会。
$ ./bench.exe
AES/CTR benchmarks...
2.7 GHz cpu frequency
3.39823 cycles per byte (cpb)
757.723 MiB per second (MiB)
第六步,为了获得最佳/最一致的结果,您需要将处理器从省电模式或低能量状态中取出。该库在Linux上使用
governor.sh来执行此操作。它位于
TestScript/目录中。
第七步,在我使用以下方式切换到CTR模式解密时:
CTR_Mode<AES>::Decryption cipher;
cipher.SetKeyWithIV(key, key.size(), key);
然后我看到批量解密的速率大致相同:
$ ./bench.exe
AES/CTR benchmarks...
2.7 GHz cpu frequency
0.579923 cycles per byte (cpb)
4440.11 MiB per second (MiB)
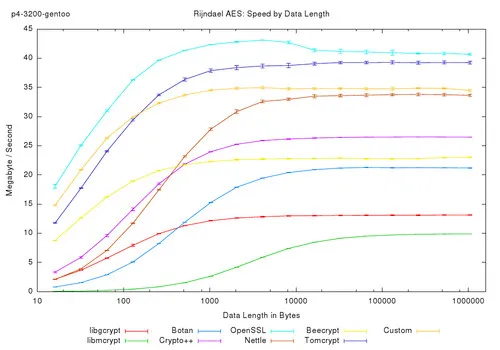
第八点,这里是一些不同机器的基准测试数据集合。在调整测试时,它应该提供一个大致的目标。
我的Beaglebone开发板运行在980 MHz时,数据传输速度是您报告的两倍。Beaglebone以无聊的40 cpb和20 MB/s的速度运行,因为它是纯C/C++,并未针对A-32进行优化。
Skylake Core-i5 @2.7 GHz
Core2 Duo @ 2.0 GHz
LeMaker HiKey Kirik SoC Aarch64 @1.2 GHz
AMD Opteron Aarch64 @2.0 GHz
BananaPi Cortex-A7 dev-board @860MHz
IBM Power8 Server @4.1 GHz
(这是一份关于不同处理器的加密库性能测试数据,包括Skylake Core-i5、Core2 Duo、LeMaker HiKey Kirik SoC Aarch64、AMD Opteron Aarch64、BananaPi Cortex-A7开发板和IBM Power8服务器。)
我的收获是:
- 在现代计算机上,CTR模式的批量加密和解密大致相同
- CTR模式的密钥设置不同,解密在现代计算机上需要更长的时间
- 小块大小比大块大小更昂贵
这正是我所期望看到的。
我认为你下一步应该使用Crypto++ wiki上的
示例程序收集一些数据,然后评估结果。