我希望将一个 multiprocessing.Queue 转换成列表。为此,我编写了以下函数:
import Queue
def dump_queue(queue):
"""
Empties all pending items in a queue and returns them in a list.
"""
result = []
# START DEBUG CODE
initial_size = queue.qsize()
print("Queue has %s items initially." % initial_size)
# END DEBUG CODE
while True:
try:
thing = queue.get(block=False)
result.append(thing)
except Queue.Empty:
# START DEBUG CODE
current_size = queue.qsize()
total_size = current_size + len(result)
print("Dumping complete:")
if current_size == initial_size:
print("No items were added to the queue.")
else:
print("%s items were added to the queue." % \
(total_size - initial_size))
print("Extracted %s items from the queue, queue has %s items \
left" % (len(result), current_size))
# END DEBUG CODE
return result
但出于某种原因它不起作用。
请观察以下的shell会话:
>>> import multiprocessing
>>> q = multiprocessing.Queue()
>>> for i in range(100):
... q.put([range(200) for j in range(100)])
...
>>> q.qsize()
100
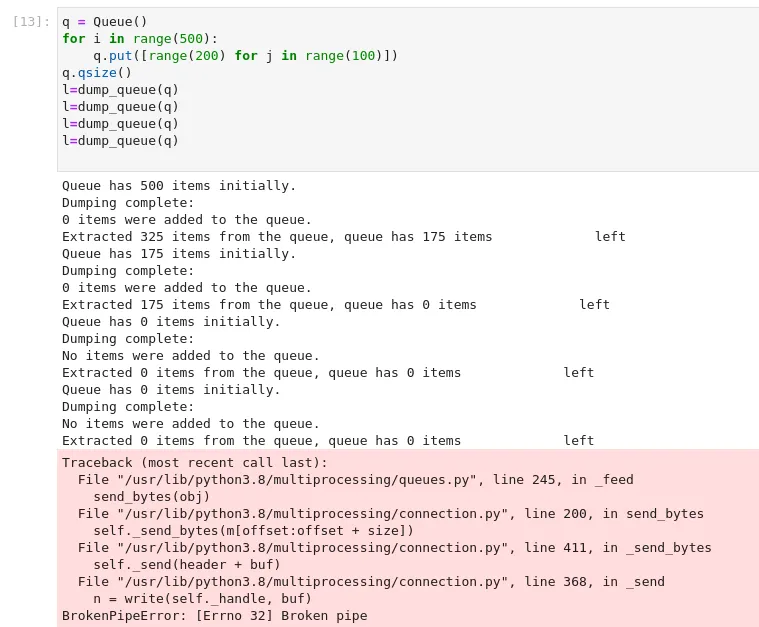
>>> l=dump_queue(q)
Queue has 100 items initially.
Dumping complete:
0 items were added to the queue.
Extracted 1 items from the queue, queue has 99 items left
>>> l=dump_queue(q)
Queue has 99 items initially.
Dumping complete:
0 items were added to the queue.
Extracted 3 items from the queue, queue has 96 items left
>>> l=dump_queue(q)
Queue has 96 items initially.
Dumping complete:
0 items were added to the queue.
Extracted 1 items from the queue, queue has 95 items left
>>>
这里发生了什么?为什么没有倾倒所有的物品?
uuid字符串作为哨兵(或者对于线程而非多进程,可以使用特定的sentinel=object()),而不是通用字符串。即便如此,如果另一个线程同时访问,则仍然可能出现问题;唯一真正安全的方式是依赖于队列内部机制,可惜这是唯一的方法!-) - Alex Martelli