我有一个包含4页的PDF文件。我想创建另一个PDF文件,其中这些页面在单个页面上依次垂直排列。用哪个命令行工具可以实现这个功能?
5个回答
7
如果您使用类Unix操作系统,可以使用pdfjam,它将Latex后端与一个简单的命令结合起来:
pdfjam --nup 1x4,landscape input.pdf
编辑:最近我使用该命令遇到了pdfjam问题。我已经通过以下方式解决:
cat input.pdf | pdfjam -nup 1x4 -landscape –outfile out.pdf
参见他们的文档:A potential drawback of pdfjam and other scripts based upon it is that any hyperlinks in the source PDF are lost
- Foxhole
5
1如果PDF文件受到密码保护,则此方法将失败。我可以通过向PDFTK指定空密码来删除此保护:
pdftk input.pdf input_pw "" output output.pdf。 - JPT@JPT 或者,您可以先解除 PDF 的保护,假设保护不相关,就像 https://dev59.com/aV7Va4cB1Zd3GeqPOvet 中所述。 - Foxhole
1在版本2.08中,正确的命令是
pdfjam --nup 1x4,landscape p1.pdf p2.pdf p3.pdf p4.pdf --outfile output.pdf。 - morgwai1FYI:“pdfjam和其他基于它的脚本的一个潜在缺点是源PDF中的任何超链接都会丢失”。 - FFish
@FFish 我会指出来的,谢谢。 - Foxhole
6
有几种方法可以完成这个任务,一种较简单,一种较难
The EASIER: A MULTIVALENT.JAR WAY
Multivalent.jar是一款惊人的免费软件,能够在pdf上执行许多有用的任务。
你可以从以下链接之一下载(sourceforge上可用的2009年multivalent.jar版本不再包含pdf工具)
你需要知道你的pdf的宽度和高度(在Linux中,你可以使用pdfinfo)
假设您的多页PDF文件是ISO A4尺寸(21x29.7cm),请键入:
使用Multivalent.jar工具的java命令,执行PDF文件排版操作,将input.pdf文件按照4x1的尺寸排版在84x29.7cm的纸张上。
这是由四个连续页面并排拼接在一起形成的结果页面:

- 生成的PDF文件 http://ge.tt/98Kv4ce/v/0
解释:
-dim 4x1 表示行数所对应的列数
-paper 84x29.7cm 表示你最终拼接的文档纸张大小,包含四个页面并排在一起。显然,在最终的PDF文件中,你将拥有四列和一行,你需要将文档宽度(21厘米)乘以4。
Multivalent可以接受英寸(-paper 33.4x11.68in)或者PostScript点数(-paper 2380x841pt)作为单位输入。
更难的:用LaTeX实现:
几年前,Peter Flynn在comp.text.pdf中提出了一种类似的任务,使用LaTeX的帮助仅通过附加pdf页面并排地完成。如果您是一个LaTeXian,可以按照以下步骤操作:
由于您需要并排附加您的单个多页pdf的四个页面,您将编写一个LaTeX导言,创建一个像这样的新文档:
假设您的pdf文档名称为input.pdf,其大小为ISO A4,并且您在工作文件夹中有此多页pdf,则会出现以下情况:
\documentclass[a4paper]{article}
\usepackage[margin=0mm,nohead,nofoot]{geometry}
\usepackage{pdfpages}
\pagestyle{empty}
\parindent0pt
\begin{document}
\includepdfmerge[nup=1x4,landscape]{input.pdf,1,input.pdf,2,input.pdf,3,input.pdf,4}
\end{document}
- Dingo
4
1感谢您指向一个好的Multivalent版本。我强烈建议从http://ge.tt/#!/21OPDHX/v/4获取它,因为其他链接会将您重定向到另一个域并要求下载.exe文件。它可能是一个自解压存档,但我怀疑它也会安装其他无用程序。 - samwyse
非常感谢;我已经用 Rapidshare 链接替换了 Ziddu 链接(即使使用 adblock 和 noscript,您也可以轻松下载 multivalent.jar 文件——exe 是 ziddu 网站的下载工具,但您可以跳过它,只下载 Multivalent.jar 文件);我认为未来最好的选择可能是添加一个种子链接。 - Dingo
在LaTeX中,如果我有4个单页PDF文件,我该怎么做? - qed
只需使用
\includepdfmerge[nup=1x4,landscape]{input1.pdf,1,input2.pdf,1,input3.pdf,1,input4.pdf,1}。 - Francesco Pasa2
我刚使用 CoherentPDF 做了这件事。
cpdf -impose-xy "0 4" in.pdf -o out.pdf
如果页面数量未知,则将其设置为更大的数字,例如
cpdf -impose-xy "0 99" in.pdf -o out.pdf
-impose-xy的x值可以设置为零,表示页面宽度无限;y值表示页面长度无限。在这两种情况下,输入文件中的页面(*)被假定为具有相同的尺寸。您可以在优秀手册中探索更多选项:
https://www.coherentpdf.com/cpdfmanual/cpdfmanualch9.html#x13-860009.2
在我的情况下,我首先必须将最后一页缩放以适应其他页面的尺寸,然后进行印刷。
cpdf \
-scale-to-fit "768pt 1024pt" -top 0 in.pdf end \
AND \
-impose-xy "99 0" in.pdf \
-o out.pdf
- FFish
0
我最近遇到了类似的问题。我需要开发一种解决方案,以预处理PDF文件,使用tabula-py包更好地识别表格。以下是我解决问题的逐步解决方案:
- 从所有
n页中删除页眉和页脚; - 将PDF拆分为包含每个单独页面的
n个文件; - 根据其边界框裁剪
n个文件中的单个页面; - 将
n个文件合并为一个包含1个页面的单个PDF,保持顺序; - 使用
tabula-py从基于文本的PDF中读取和预处理表格。
在我的情况下,该过程的第3步可能会生成具有不同尺寸的文件。当使用pdfjam命令时,即使使用--pagetemplate参数,在第4步中对齐页面也会出现问题。对我来说,垂直对齐是最糟糕的。
幸运的是,我能够使用基于LaTeX的方法解决这个页面对齐问题。以下是我使用的基本源代码--将所有文件放在同一个目录中。
这篇文章的答案在“Shell脚本”部分,从“使用LaTeX将'n'页合并为单个页面开始......”。
要求:
我使用Debian Linux发行版测试了这个解决方案。要在Windows上工作,您可以例如通过WSL安装Debian。假设您正在使用Debian或Ubuntu,请运行以下命令:
sudo apt update
sudo apt install texlive-extra-utils texlive-latex-extra poppler-utils ghostscript default-jdk -y
由于PDF预处理的结果,最终文件的尺寸可能会缩小,特别是宽度。即使它是矢量化的,缩小PDF的大小对使用
tabula-py工具提取表格的质量有负面影响。为了增加最终PDF文件的大小并保持纵横比,我们可以使用
cpdf工具。如果使用Linux发行版,只需将二进制文件复制到与Shell脚本相同的目录中。然后给予二进制文件执行权限:chmod +x cpdf
LaTeX 模板:
创建一个名为 pdf_merge_template.tex 的文件,内容如下:
\documentclass[dvipdfmx]{article}
\usepackage[margin=0in]{geometry}
\usepackage{pdfpages}
\begin{document}
\centering<PDF-PAGES>
\end{document}
Shell脚本:
创建一个名为pdf-preprocessing.sh的文件,内容如下:
#!/bin/bash
# References
# ----------
# [PDF preprocessing] https://dev59.com/2WQo5IYBdhLWcg3wXeT5#71802078
PDF_MERGE_TEMPLATE_FILENAME="pdf_merge_template.tex"
PDF_MERGE_TEMPLATE_PAGES_MACRO="<PDF-PAGES>"
CPDF_FILENAME="cpdf" # Binary file of "Coherent PDF" tool.
INPUT_FILEPATH=$1
OUTPUT_FILEPATH=$2
if [ "$#" -eq "2" ]; then
echo "Starting PDF preprocessing..."
else
echo "ERROR: Wrong arguments ('INPUT_FILEPATH', 'OUTPUT_FILEPATH')!"
exit
fi
TEMP_DIR_PATH=$(mktemp -d)
echo "Setting up working directory: ${TEMP_DIR_PATH}"
THIS_FILENAME=$(readlink -f "$0")
THIS_DIR=$(dirname "$THIS_FILENAME")
PDF_MERGE_TEMPLATE_PATH="${THIS_DIR}/${PDF_MERGE_TEMPLATE_FILENAME}"
CPDF_BIN_PATH="${THIS_DIR}/${CPDF_FILENAME}"
echo "Removing header and footer from all pages..."
# Removing header and footer from PDF pages based on margin settings (e.g., '5 -75 5 -25'):
pdfcrop --margins '5 -75 5 -25' "${INPUT_FILEPATH}" "${TEMP_DIR_PATH}/input-tmp.pdf"
# Deleting the textual content of the cut parts:
pdftocairo "${TEMP_DIR_PATH}/input-tmp.pdf" "${TEMP_DIR_PATH}/input.pdf" -pdf
# Counting the number of pages from PDF:
NUM_PAGES=$(pdfinfo "${TEMP_DIR_PATH}/input.pdf" | awk '/^Pages:/ {print $2}')
REL_PAGE_WIDTH=$(python -c "print(1 / ${NUM_PAGES})")
PAGES_LIST=""
echo "Cropping each page based on its specific bounding box..."
for i in $(seq 1 $NUM_PAGES)
do
# Splitting current page:
pdfjam "${TEMP_DIR_PATH}/input.pdf" $i --outfile "${TEMP_DIR_PATH}/page_${i}-tmp.pdf"
# Fetching bounding box of current page:
PAGE_WIDTH=$(pdfinfo "${TEMP_DIR_PATH}/page_${i}-tmp.pdf" | awk '/^Page size:/ {print $3}')
BBOX=$(gs -dBATCH -dNOPAUSE -q -sDEVICE=bbox "${TEMP_DIR_PATH}/page_${i}-tmp.pdf" 2>&1 | awk '/^%%HiResBoundingBox:/ {print 0 " " $3 " " '${PAGE_WIDTH}' " " $5}')
# Removing content out of current page's bounding box:
PAGE_FILENAME="page_${i}"
PDF_FILEPATH="${TEMP_DIR_PATH}/${PAGE_FILENAME}.pdf"
PS_FILEPATH="${TEMP_DIR_PATH}/${PAGE_FILENAME}.ps"
gs -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -dCompatibilityLevel=1.5 -sOutputFile=$PDF_FILEPATH -c "[/CropBox [${BBOX}] /PAGES pdfmark" -f "${TEMP_DIR_PATH}/page_${i}-tmp.pdf"
PAGES_LIST="${PAGES_LIST}\n \\\includegraphics[width=${REL_PAGE_WIDTH}\\\textwidth]{${PDF_FILEPATH}} \\\\\\\ \\\vspace{-0.03cm}"
done
echo "Merging the 'n' pages into a single one using LaTeX..."
cp $PDF_MERGE_TEMPLATE_PATH "${TEMP_DIR_PATH}/merged.tex"
sed -i "s#${PDF_MERGE_TEMPLATE_PAGES_MACRO}#${PAGES_LIST}#g" "${TEMP_DIR_PATH}/merged.tex"
latex -halt-on-error -output-directory $TEMP_DIR_PATH "${TEMP_DIR_PATH}/merged.tex"
dvipdfm "${TEMP_DIR_PATH}/merged.dvi" -o "${TEMP_DIR_PATH}/merged.pdf"
echo "Finalizing the PDF and sending a copy to the destination directory..."
# Adding margins to the final PDF:
pdfcrop --margins 5 "${TEMP_DIR_PATH}/merged.pdf" "${TEMP_DIR_PATH}/output-tmp.pdf"
# Enlargement of the final PDF file to extract tables correctly using the "tabula-py" tool:
$CPDF_BIN_PATH -scale-page "10 10" "${TEMP_DIR_PATH}/output-tmp.pdf" -o "${TEMP_DIR_PATH}/output.pdf"
# Copying the pre-processed PDF file to the output path:
cp "${TEMP_DIR_PATH}/output.pdf" "${OUTPUT_FILEPATH}"
echo "Deleting temp files..."
rm -rf "${TEMP_DIR_PATH}"
使用以下命令为脚本赋予执行权限:
chmod +x pdf-preprocessing.sh
使用示例:
要预处理名为example.pdf的文件,只需运行以下命令:
sh pdf-preprocessing.sh example.pdf preprocessed-example.pdf
根据您的情况编辑脚本参数。例如,页眉和页脚坐标将取决于您文件的模板。欢迎提出改进和简化建议。
- joao8tunes
0
一种选择是使用
或者使用
创建4个PDF页面的LaTeX代码。
将PDF输出转换为PNG格式。
pdfxup。-o .. 输出文件-x .. 每页的列数-y .. 每页的行数-fw 0 .. 将删除页面周围的边框pdfxup -o out.pdf -x 4 -y 1 input.pdf

-l .. 横屏模式
pdfxup -o out.pdf -x 1 -y 4 -l 0 input.pdf
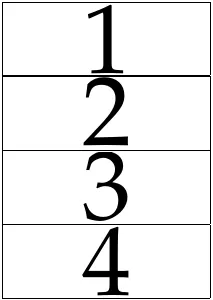
pdfxup -o out.pdf -x 2 -y 2 -l 0 input.pdf
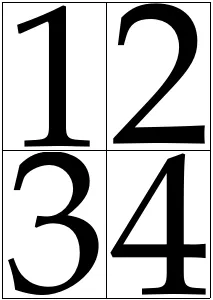
pdfxup -o out.pdf -x 2 -y 2 -l 0 -col input.pdf

或者使用
pdfjam。pdfjam --outfile out.pdf --nup 4x1 --landscape input.pdf
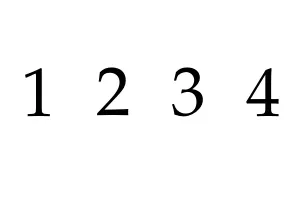
pdfjam --outfile out.pdf --nup 1x4 input.pdf

pdfjam --outfile out.pdf --nup 2x2 input.pdf
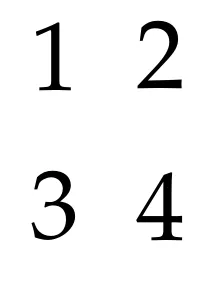
pdfjam --outfile out.pdf --nup 2x2 --column true input.pdf
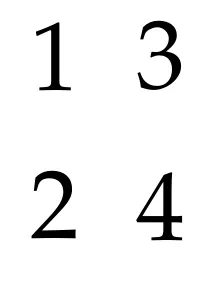
创建4个PDF页面的LaTeX代码。
\documentclass{article}
\pagestyle{empty}
\begin{document}
\fontsize{\textheight}{\textheight}
\fontfamily{ppl}\selectfont
\centering
1\\2\\3\\4
\end{document}
将PDF输出转换为PNG格式。
pdftoppm -singlefile -scale-to 300 out.pdf out -png
- GKi
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
pfdunite可以实现你想要的功能... - Basile Starynkevitchpdfunite将多个 PDF 合并成一个具有多个页面的 PDF,但这不是 OP 想要的。 - qed