我想以特定顺序迭代一个整数一维数组/向量,但我无法理解如何设置循环条件。输入数据是一个整数一维向量:
{1, 5, 9, 13, 17, 21, 2, 6, 10, 14, 18, 22, 3, 7, 11, 15, 19, 23, 4, 8, 12, 16, 20, 24, 25, 29, 33, 37, 41, 45, 26, 30, 34, 38, 42, 46, 27, 31, 35, 39, 43, 47, 28, 32, 36, 40, 44, 48}
这个输入数据实际上是一个带有子组的二维数组/网格的一维表示:
+----+----+----+----+----+----+
| 1 | 5 | 9 | 13 | 17 | 21 |
+----+----+----+----+----+----+
| 2 | 6 | 10 | 14 | 18 | 22 |
+----+----+----+----+----+----+
| 3 | 7 | 11 | 15 | 19 | 23 |
+----+----+----+----+----+----+
| 4 | 8 | 12 | 16 | 20 | 24 |
+----+----+----+----+----+----+
| 25 | 29 | 33 | 37 | 41 | 45 |
+----+----+----+----+----+----+
| 26 | 30 | 34 | 38 | 42 | 46 |
+----+----+----+----+----+----+
| 27 | 31 | 35 | 39 | 43 | 47 |
+----+----+----+----+----+----+
| 28 | 32 | 36 | 40 | 44 | 48 |
+----+----+----+----+----+----+
这个表格被分成了多个2x4的子组:
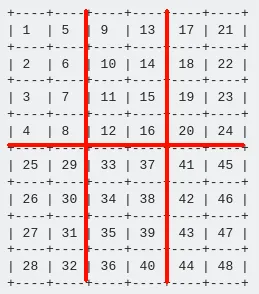
我想按照数字指示的顺序迭代这个一维输入向量/数组。(从头到尾依次遍历每个2x4的子组)。 在循环中,我想把当前处理的子组的8个元素装入一个向量/整数进行进一步处理。 最终,我应该处理6个子组,第一个子组包含1到8的数字,第二个子组包含9到16,以此类推... 子组应从左到右处理。
注意: 输入数据中的数字仅用作示例,以明确应处理数据的顺序。输入数据可以包含完全随机的值。应保留每个组中值的顺序。组内不应排序/重新排序。重要的是子组/数组维度等约束条件。
除了一维数组/向量之外,我还知道网格的尺寸和子组的大小:
int grid_width = 6; // Variable, but will always be a multiple of 2, to match subgroup width
int grid_height = 8; // Variable, but will always be a multiple of 4, to match subgroup height
const int group_width = 2; // Constant, subgroup width is always 2.
const int group_height = 4; // Constant, subgroup height is always 4.
我的想法是使用一个循环迭代整个数据集,然后再用两个循环来分别处理子组。但我在循环条件和元素索引上感到很困难。我的思考过程大致如下:
// Iterate over entire data
for (int i = 0; i < grid_width * grid_height; i += (group_width * group_height))
{
int block[8];
// Iterate groups in correct order
for (int j = 0; j < group_height; j++)
{
for (int k = 0; k < group_width; k++)
{
// Grab current element in group
int value = input_array[i * grid_width + j]; // ?? This ain't right
// Add element to group array/vector
block[??] = ??;
}
}
// Do further processing with the group array
}
有人能帮我正确地循环这个吗?希望问题已经足够清楚了,如果不清楚,请告诉我。
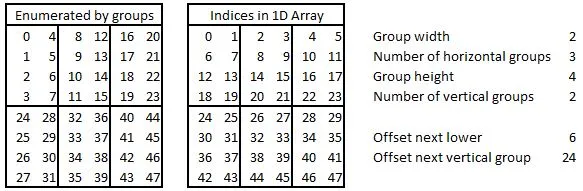
{ 0, 6, 12, ... etc }一样开始。通过这种方式,你也应该很快开始看到出现的模式,这意味着你可以根据你对矩阵和子矩阵的信息在运行时创建此索引向量。 - Some programmer dude1, 2, 3, 4, 5, 6, 7, 8,在第二次迭代时输出数字9, 10, 11, 12, 13, 14, 15, 16等等,这是微不足道的。 - alani